Welcome to Doom9's Forum, THE in-place to be for everyone interested in DVD conversion. Before you start posting please read the forum rules. By posting to this forum you agree to abide by the rules. |
 15th April 2021, 23:55
15th April 2021, 23:55
|
#221 | Link |
|
Registered User
Join Date: Mar 2018
Posts: 447
|
Zopti v1.1.0 released
A new major release is here! Zopti now supports executing multiple scripts simultaneously which can lead to very nice performance improvement. This can be very useful when the script itself is not able to utilize all of your cores.
Here's the full release info:
Download link is at the first post. I will shortly post some data on the multithreading performance. |

|

|
|
16th April 2021, 00:32
|
#222 | Link |
|
Registered User
Join Date: Mar 2018
Posts: 447
|
I tested the new -threads argument using the denoising tutorial script, this time using GMSD as the similarity metric and using 50 frames instead of 5. Here's the script:
Code:
SetCacheMode(0)
TEST_FRAMES = 50 # how many frames are tested
MIDDLE_FRAME = 100 # middle frame number
RawSourcePlus("D:/optimizer/test/flower/flower_cif.yuv", width=352, height=288, pixel_type="I420")
source=ColorYUV(levels="PC->TV")
noisy=source.AddGrain(25, 0, 0, seed=1)
#denoised=noisy.FFT3DFilter(sigma=4, bt=4, bw=16, bh=16, ow=8, oh=8) # best settings by Fizick
sigma = 400/100.0 # optimize sigma = _n_/100.0 | 400..600 ; filter:x 5 % 0 == | sigma
bt = 5 # optimize bt = _n_ | 3,5 | blockTemporal
blockSize = 14 # optimize blockSize = _n_ | 6,12 ; min:overlap 2 * | blockSize
overlap = 16 # optimize overlap = _n_ | 4..6 ; max:blockSize 2 / | overlap
denoised=noisy.FFT3DFilter(sigma=sigma, bt=bt, bw=blockSize, bh=blockSize, ow=overlap, oh=overlap)
# cut out the part used in quality / speed evaluation
source = source.Trim(MIDDLE_FRAME - TEST_FRAMES/2 + (TEST_FRAMES%2==0?1:0), MIDDLE_FRAME + TEST_FRAMES/2)
denoised = denoised.Trim(MIDDLE_FRAME - TEST_FRAMES/2 + (TEST_FRAMES%2==0?1:0), MIDDLE_FRAME + TEST_FRAMES/2)
last = denoised
last = GMSD(source, denoised, show=false)
# measure runtime, plugin writes the value to global avstimer variable
global avstimer = 0.0
AvsTimer(frames=1, type=0, total=false, name="Optimizer")
# per frame logging (gmsd, time)
global delimiter = "; "
global resultFile = "perFrameResults.txt" # output out1="gmsd: MIN(float)" out2="time: MIN(time) ms" file="perFrameResults.txt"
# write "stop" at the last frame to tell the optimizer that the script has finished
global frame_count = FrameCount()
WriteFileIf(resultFile, function() {
current_frame == frame_count-1
}, function() {
gmsd = 0.0
str = ""
for (i = 0, frame_count-1) {
value = propGetFloat("_PlaneGMSD", offset = -i)
gmsd = gmsd + value
if (i>0) { str = str + e"\n" }
str = str + string(current_frame - i) + delimiter + string(value) + delimiter + string(avstimer)
}
return str + e"\nstop " + string(gmsd)
}, append=false)
return last
The script only has 246 valid parameter combinations to test so we can try all of them using Code:
zopti denoise_ex.avs -alg exhaustive -threads 1  The best result is about 20 seconds using 16 threads (on a Ryzen 3900X which has 12 cores / 24 threads). Another way to look at the scaling is to calculate how much faster we get the results when using -threads:  Using 16 threads is 8,6 times as fast as using only one thread. Of course this is just one data point and I don't mean to imply that you can always get such a performance improvement. I would have liked to include more tests using more real-world usage scenarios (HD source etc) but my stock cooled processor cannot handle those for more than a few seconds, it becomes so hot that my PC shuts down.  Comparing AviSynth and VapourSynth it looks like VS has the edge when using one or just a few threads, but the differences almost vanish when using 12 or more threads. The VS is also able to utilize more than 16 cores while with AVS the performance starts to degrade. The point where more threads are just slowing down is probably dependent on the specific script, I will have to run more tests on that. Last edited by zorr; 16th April 2021 at 00:58. |
|
|
|
|
16th April 2021, 05:14
|
#223 | Link |
|
Pig on the wing

Join Date: Mar 2002
Location: Finland
Posts: 5,731
|
Thanks zorr, looks like a very handy approach. I'll try testing it over the weekend.
__________________
And if the band you're in starts playing different tunes I'll see you on the dark side of the Moon... |
|
|
|
|
4th May 2021, 10:32
|
#224 | Link |
|
Acid fr0g

Join Date: May 2002
Location: Italy
Posts: 2,577
|
Let's say I want to do compression/quality tests on 1-3% of a whole movie, changing the parameters on SMDegrain in a fixed range, mostly tr and thSAD.
Is there a way to batch that process? Usually I have to manually set a frame range and have multiple avs scripts. Can you help me? My usual script, with the parts I want to have permutations in red: SetFilterMTMode("DEFAULT_MT_MODE", 2) LoadPlugin("D:\Eseguibili\Media\DGDecNV\DGDecodeNV.dll") DGSource(something) SMDegrain (tr=4, thSAD=400, refinemotion=false, n16_out=true, mode=0, contrasharp=false, PreFilter=4, truemotion=true, plane=4, chroma=true) Prefetch(6)
__________________
@turment on Telegram |
|
|
|
|
4th May 2021, 21:42
|
#225 | Link | |
|
Registered User
Join Date: Mar 2018
Posts: 447
|
Quote:
If you use your own eyes to measure the quality and just want to generate the different versions... well, Zopti doesn't output any video so it can't help you there. But it could generate you the different script variations if you provide a file with the parameter combinations you want, like this Code:
1 tr=4 thSAD=40 1 tr=5 thSAD=40 1 tr=4 thSAD=50 etc. |
|
|
|
|
|
28th May 2021, 21:35
|
#227 | Link |
|
Registered User
Join Date: Mar 2018
Posts: 447
|
Zopti v1.2.0 released
Time for a new update! This version has some major additions so I bumped the version to 1.2.0.
And here's what -vismode history looks like:  The black thick line shows the best found value of the chosen parameter. The red diamonds indicate a point where a new best result has been found and this parameter's value was changed. The white diamonds indicate a new best result but this parameter's value remained the same. In the example optimization was finished and then restarted with different settings at around 190 000 iterations. The -timeout was needed when I started running MVTools2 tests with all the parameters and it turned out that some combinations took an enormous amount of time to finish (typical time was 5 seconds but some combinations took over 30 minutes...). Using a timeout of 60 seconds solved that problem. -continue is useful if you want to keep optimizing a result that is finished, you can try different settings. Also very handy when the optimization has been aborted by hardware failure or something like Windows update... you can just restart it using the same settings. This also makes it possible to run huge iteration counts little by little even if you need/want to use the computer for other things once in a while.  Download link updated at first post. |
|
|
|
|
13th September 2021, 13:04
|
#228 | Link |
|
Registered User
Join Date: Nov 2009
Posts: 2,361
|
Hey thanks a lot for the tool. I plan to use it now heavily, is it possible to combine it with VMAF? I tweaked your GMSD client script but VMAF doesn't seem to write frameProps, not at least as _PlaneVMAF.
By the way, if you need to combine/merge arrays (didn't read what for) I made this function (you need to explicitly declare the args in the call): Code:
function ArrayAdd( val_array "a", val_array "b") {
as = ArraySize(a)-1
bs = ArraySize(b)-1
na = ""
for (i = 0, as+bs+1, 1) {
o = i - as - 1
cm = i != as+bs+1 ? "," : ""
na = na + ( i > as ? String(Eval(Format("b[{o}]"))) : \
String(Eval(Format("a[{i}]")))) + cm
}
return Eval("["+na+"]") }
__________________
i7-4790K@Stock::GTX 1070] AviSynth+ filters and mods on GitHub + Discussion thread |
|
|
|
|
13th September 2021, 23:25
|
#229 | Link | ||
|
Registered User
Join Date: Mar 2018
Posts: 447
|
Quote:
But before you start using it you might want to check these tests I conducted (there's more tests in that thread) about the different similarity metrics, seems like VMAF is not very consistent and sometimes gives downright bad results. Quote:
Last edited by zorr; 13th September 2021 at 23:57. Reason: Added VMAF parameter instructions |
||
|
|
|
|
14th October 2021, 23:33
|
#230 | Link |
|
Registered User
Join Date: Nov 2009
Posts: 2,361
|
zorr, I'm trying to come up with a self resolving BBSIM function, I have troubles with SSIM_FRAME(), not only it requires 8-bit but it's output value isn't affected by the filtered clip. I tried to implement reading _PlaneSSIM property if created with vsSSIM but its output value is very different from SSIM_FRAME().
This is my attempt at normalizing PlaneSSIM to SSIM_FRAME (by /335 and then 2*bssim). Code:
function BSSIM(clip source, clip filtered, bool "PlaneSSIM", bool "show", bool "fulls") {
show = Default(show, false)
PS = Default(PlaneSSIM, false)
fs = Default(fulls, false)
blurred = source.ex_blur(1.5*2,bifit=true,UV=1)
source8 = PS ? source : source.ConvertBits(8, dither=-1, fulls=fs)
blurred8 = PS ? blurred : blurred.ConvertBits(8, dither=-1, fulls=fs)
scharr_orig = ex_edge(source8, "pscharr",0,255)
scharr_blurred = ex_edge(blurred8, "pscharr",0,255)
source = PS ? source.ConvertBits(32, fulls=fs) : source8
blurred = PS ? blurred.ConvertBits(32, fulls=fs) : blurred8
scharr_orig = PS ? scharr_orig.ConvertBits(32, fulls=fs) : scharr_orig
scharr_blurred = PS ? scharr_blurred.ConvertBits(32, fulls=fs) : scharr_blurred
ScriptClip(source, function [source, blurred, scharr_orig, scharr_blurred, PS, show] () {
SSIM = PS ? propGetFloat(source,"_PlaneSSIM")/335 : \
SSIM_FRAME(source, blurred)
stddev_orig = RT_YPlaneStdev(scharr_orig)
stddev_alt = RT_YPlaneStdev(scharr_blurred)
bssim = SSIM * (2*stddev_orig*stddev_alt) / (stddev_orig*stddev_orig + stddev_alt*stddev_alt)
bssim = PS ? 2*bssim : bssim
propSet("_PlaneBSSIM", bssim, 0)
return show ? Subtitle("PlaneBSSIM: " + String(bssim)) : last } ) }
__________________
i7-4790K@Stock::GTX 1070] AviSynth+ filters and mods on GitHub + Discussion thread |
|
|
|
|
15th October 2021, 00:05
|
#231 | Link | ||
|
Registered User
Join Date: Mar 2018
Posts: 447
|
Quote:
 Quote:
|
||
|
|
|
|
15th October 2021, 10:02
|
#232 | Link |
|
Registered User
Join Date: Nov 2009
Posts: 2,361
|
haha, yes didn't notice. I thought 'blurred' was a preprocessing.
Well, I think this will do it. (EDIT: I need to fix vsSSIM as I borked it when optimizing it) Code:
function BSSIM(clip source, clip blurred, bool "PlaneSSIM", bool "show", bool "fulls") {
show = Default(show, false)
PS = Default(PlaneSSIM, false) # Set to True if the clip has the _PlaneSSIM frame property
fs = Default(fulls, false)
source8 = source.ConvertBits(8, dither=-1, fulls=fs)
blurred8 = blurred.ConvertBits(8, dither=-1, fulls=fs)
scharr_orig = ex_edge(source8, "pscharr",0,255)
scharr_blurred = ex_edge(blurred8, "pscharr",0,255)
ScriptClip(source, function [source, source8, blurred8, scharr_orig, scharr_blurred, PS, show] () {
SSIM = PS ? propGetFloat(source,"_PlaneSSIM") : \
SSIM_FRAME(source8, blurred8) # only works on 8-bit
stddev_orig = RT_YPlaneStdev(scharr_orig) # only works on 8-bit (output is also 8-bit)
stddev_alt = RT_YPlaneStdev(scharr_blurred) # only works on 8-bit (output is also 8-bit)
bssim = SSIM * (2*stddev_orig*stddev_alt) / (stddev_orig*stddev_orig + stddev_alt*stddev_alt)
propSet("_PlaneBSSIM", bssim, 0)
return show ? Subtitle("PlaneBSSIM: " + String(bssim)) : last } ) }
__________________
i7-4790K@Stock::GTX 1070] AviSynth+ filters and mods on GitHub + Discussion thread Last edited by Dogway; 15th October 2021 at 10:19. |
|
|
|
|
17th January 2022, 14:49
|
#233 | Link |
|
Registered User
Join Date: Nov 2009
Posts: 2,361
|
I'm running some tests for motion vectors and I have a few questions.
-How do you terminate the process? Normally I 'ctrl+c' on the console but then I have to kill each avsr64.exe process -What is the best approach to simply run a bunch of random iterations without any refinement? I simply used low iterations with high number of runs, but 'runs' doesn't allow multithreading, and 'timeout' finishes the whole thing. The problem here is that some settings have more weight than others so it can bias the refinement so I want to give equal probability to all of them to draw some conclusions (ie. in Excel), at least for the initial tests. Code:
SET RUNS= 4 SET ALG= mutation SET POPULATION= 4 SET INITIAL= random SET ITERS= dyn SET MUTAMOUNT= 0.5 0.01 SET MUTCOUNT= 60% 1 SET CROSSPROB= 0.1 SET CROSSDIST= 20 SET SENSITIVITY= TRUE SET DYNPHASES= 1 SET DYNITERS= 8 SET ERRORS= STOP SET PRIORITY= SET THREADS= 4 SET TIMEOUT= 410 SET CONTINUE= java -jar Zopti.jar "..\Zopti_test.avs" ^ -alg %ALG% -initial %INITIAL% -iters %ITERS% -dyniters %DYNITERS% -dynphases %DYNPHASES% -pop %POPULATION% -runs %RUNS% -mutcount 1 -mutamount %MUTAMOUNT% -timeout %TIMEOUT% -threads %THREADS% -Also I tried to kill some iterations as soon as some frames are rendered longer than necessary so I played a bit with WriteFileIf() but didn't find what keyword is for timeout. Tested with: Code:
WriteFileIf(resultFile, "avstimer > 4500.0", """ 0.0 9999999"""+Chr(10)+""" "stop " """, append=true)
__________________
i7-4790K@Stock::GTX 1070] AviSynth+ filters and mods on GitHub + Discussion thread |
|
|
|
|
17th January 2022, 23:09
|
#234 | Link | |||||
|
Registered User
Join Date: Mar 2018
Posts: 447
|
Quote:
Quote:
Quote:
Quote:
Quote:
|
|||||
|
|
|
|
19th January 2022, 22:56
|
#235 | Link |
|
Registered User
Join Date: Mar 2018
Posts: 447
|
Zopti v1.2.1 released
I implemented a shutdown hook to kill all the running subprocesses if Zopti is terminated (thanks for the idea Dogway). I had some other changes in the pipeline as well, so here's a new release:
Here's what -vismode line looks like: 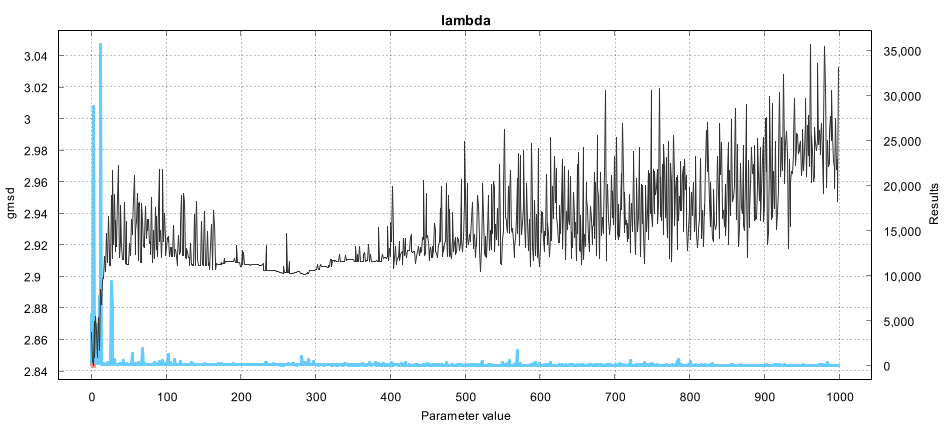 Download link updated at first post. |
|
|
|
|
20th January 2022, 13:36
|
#236 | Link |
|
Registered User
Join Date: Nov 2009
Posts: 2,361
|
Thanks for the update!!
I got some issues with sensitivity option. Probably my optimization range in the script wasn't too broad or something and I was getting this error message after DYNITERS iterations using "mutation" as algo, and "dyn" as iterations. Code:
Parameter sensitivity estimation with 256 result combinations
java.lang.ArrayIndexOutOfBoundsException: Index -700 out of bounds for length 23
00
at avisynthoptimizer.Parameter.updateAverages(Parameter.java:954)
at avisynthoptimizer.Parameter.updateSensitivityEstimation(Parameter.jav
a:970)
at avisynthoptimizer.SensitivityEstimation.estimateParameterSensitivity(
SensitivityEstimation.java:102)
at avisynthoptimizer.AviSynthOptimizer.optimize_mutation_multithreaded(A
viSynthOptimizer.java:4726)
at avisynthoptimizer.AviSynthOptimizer.main(AviSynthOptimizer.java:620)
ERROR: Index -700 out of bounds for length 2300
C:\Program Files (x86)\AviSynth+\Authors\zorr\Zopti-1.2.0>rem ERROR: Series name
>phase 1,00< has already been used. Use unique names for each series!!!
By the way on another note I was trying to evaluate motion vectors as a general case without the intervention of client functions like MFlowFPS, or MDegrain by using the SAD mask in MMask (kind=1) and using the average value as the frame metric. Well this didn't yield good results, it tends to optimize to a large searchRange while for example MDegrain with a searchRange over 2 smears the content. So first I'm locking searchRange to 2 and optimizing for MDegrain with the MDegrain client. Also most of the hardest settings to optimize are those of truemotion, lambda, pnew, pzero, badSAD, badRange, plevel, temporal, global... they show bad correlation overall. Here's my Excel chart for the first randomized data samples. You can easily see that any other than DCT=0 is slow and bad quality, so you can remove those entries and continue guessing settings that can be locked down. Ideally one would run some multivariate analysis but I'm still studying statistics. Google Spreadsheets
__________________
i7-4790K@Stock::GTX 1070] AviSynth+ filters and mods on GitHub + Discussion thread Last edited by Dogway; 21st January 2022 at 15:40. |
|
|
|
|
22nd January 2022, 00:12
|
#237 | Link | |||||
|
Registered User
Join Date: Mar 2018
Posts: 447
|
Quote:
Quote:
Quote:
Note that you don't need truemotion if you set lambda, lsad, pnew, plevel and global in your script as those values will overwrite whatever truemotion sets them to. Quote:
Maybe you've already seen this but I did some pretty extensive tests with MVTools frame interpolation and found that dct=1 was consistently best, it was the winner in three test runs with at least 100000 iterations each. It could very well be that dct=0 is the best for MDegrain and also it may have more to do with the specific video, as even I haven't done tests with multiple videos to find out which parameters are consistently best with most source material (or perhaps none are, or perhaps it depends on the resolution or content type). In any case 100 tests is not enough to say anything sure. I try to make conclusions on the best value only after Zopti has consistently selected it as the best one, after which it can be locked down and another tests can focus on finding the best values for the remaining unlocked parameters. MVTools has so many parameters that it's a real challenge to optimize them due to enormous search space, that's why it has to be done meticuously and using large iteration counts. Quote:
|
|||||
|
|
|
|
22nd January 2022, 10:07
|
#238 | Link | |
|
Registered User
Join Date: Nov 2009
Posts: 2,361
|
The error didn't happen to me in my last edit, I think it was related to the parameter range AND the "filter:" used. It will happen again I guess so I will post the offending script here.
Currently I'm benchmarking MDegrain since MFlowFPS was a bit too complex and as you say DCT=1 was the best. DCT=1 and searchAlgo=3 are the slowest settings in MAnalyse aside of a high searchRange, so it would be difficult to find a pareto front with them. In the case of MDegrain I don't feel they are critical (did some runs) so I exclude them. Quote:
I don't know how you can run so many iterations, I'm testing with 150 frames and as you can see it takes about 2 to 5 minutes per iteration (taking out DCT=1 and search=3). I run 8 scripts at the same time each for a thread on my CPU. What I did, instead of adding grain to a clean clip, I did my best to degrain a clip employing all sorts of tricks, then try to mimic that with basic MDegrain. Here's my reference clip (a sample from @tormento). Code:
setmemorymax(2048)
DGSource("brazil.dgi",cl=0,ct=40,cr=0,cb=40)
ConvertBits(16,fulls=true)
pre=smdegrain(tr=1,mode="temporalsoften",blksize=16,thSAD=900,LFR=400,prefilter=3,DCTFlicker=true,contrasharp=false,refinemotion=true).ex_unsharp(0.5, 1920.0/8, 0.0)
smdegrain(tr=2,mode="MDegrain",blksize=16,prefilter=pre,thSAD=400,LFR=200,contrasharp=true,refinemotion=true)
ConvertBits(8,dither=1)
Code:
setmemorymax(16384/8)
DGSource("brazil-ref.dgi",cl=0,ct=0,cr=0,cb=0)
trim(1,12)+\
trim(60,96)+\
trim(173,285-12)
src=last
DGSource("brazil.dgi",cl=0,ct=40,cr=0,cb=40)
AssumeFPS(24000,1001)
RequestLinear(30)
thSAD = 285 # optimize thSAD = _n_ | 230..290 ; filter:x 5 % 0 == | thSAD
thSADC = 200 # optimize thSADC = _n_ | 140..250 ; filter:x 10 % 0 == | thSADC
thSADR = 280 # optimize thSADR = _n_ | 150..300 ; filter:x 10 % 0 == | thSADR
BlkSize = 16
BlkSizeR = 8
overlap = 4
overlapR = 4
pel = 1
sharp = 2 # optimize sharp = _n_ | 2 | sharp
scaleCSAD = 2
trymany = false
truemotion = false # optimize truemotion = _n_ | true,false | truemotion
truemotionR = true # optimize truemotionR = _n_ | false,true | truemotionR
temporal = true # optimize temporal = _n_ | true,false | temporal
# Settings that depend on source noise
# lsad the noisier the lower
# sigma the noisier the higher
# badSAD
# TRUEMOTION SETTINGS
lambda = 440 # optimize lambda = _n_ | 400..900 ; filter:x 10 % 0 == | lambda
# lambdaR normally optimizes between 1.6 and 2.0 times lambda
lambdaR = 1320 # optimize lambdaR = _n_ | 960..2000 ; min:lambda ; max:lambda 3 * ; filter:x 20 % 0 == | lambdaR
# pnew: Default is 0 for truemotion = false and 50 for truemotion = true.
pnew = 114 # optimize pnew = _n_ | 100..200 ; filter:x 2 % 0 == | pnew
pnewR = 136 # optimize pnewR = _n_ | 100..250 ; filter:x 2 % 0 == | pnewR
# lambda is not used when pzero is 0 (zero vector)
# there's a relationship between pzero and searchRangeR (and searchRangeR with searchRangeFinest)
pzero = 100 # optimize pzero = _n_ | 28..100 ; filter:x 2 % 0 == | pzero
lsad = 6000 # optimize lsad = _n_ | 1000..8000 ; filter:x 100 % 0 == | lsad
# plevel: Default is 0 for truemotion = false and 50 for truemotion = true
plevel = 79 # optimize plevel = _n_ | 1..99 ; filter:x 2 % 0 != | plevel
lvl = 1 # typically plevel is set same as level
# lambda is not used for global predictor
pglobal = 8 # optimize pglobal = _n_ | 0..20 | pglobal
badrange = 2 # optimize badrange = _n_ | 0..50 ; filter:x 2 % 0 == | badrange
badSAD = 1350 # optimize badSAD = _n_ | 1100..2200 ; filter:x 50 % 0 == | badSAD
dct = 0 # optimize dct = _n_ | 0 | dct
dctre = 9 # optimize dctre = _n_ | 0,2,3,6,7,9 | dctre
rfilter = 3
searchAlgo = 1 # optimize searchAlgo = _n_ | 1 | searchAlgo
searchAlgoR = 4 # optimize searchAlgoR = _n_ | 0,1,2,4,5 | searchAlgoR
searchRange = 15 # optimize searchRange = _n_ | 2..17 | searchRange
searchRangeR = 13 # optimize searchRangeR = _n_ | 2..18 | searchRangeR
searchRangeFinest = 17# optimize searchRangeFinest = _n_ | 9..20 | searchRangeFinest
sglobal = true # optimize sglobal = _n_ | true,false | sglobal
trim(1,12)+\
trim(60,96)+\
trim(173,285-12)
C=ConvertBits(16,fulls=false)
pre=C.ex_FluxSmoothST(2,2,255,0,false,UV=3).ex_Luma_Rebuild(s0=3,tv_range=true).ConvertBits(8,dither=-1,fulls=true)
Recalculate=true
superfilt = MSuper(pre, hpad=16, vpad=16, sharp=sharp, rfilter=rfilter, pel=pel, mt=false)
superR = MSuper(C, hpad=16, vpad=16, levels=lvl, sharp=sharp, rfilter=rfilter, pel=pel, mt=false, chroma=false)
superRe = MSuper(pre, hpad=16, vpad=16, levels=lvl, sharp=sharp, rfilter=rfilter, pel=pel, mt=false)
bak2 = MAnalyse(superfilt, isb=true, delta=2, blksize=BlkSize, overlap = overlap, search=searchAlgo, searchparam=searchRange, pelsearch=searchRangeFinest, dct=dct, mt=false, scaleCSAD=scaleCSAD, pnew=pnew, pzero=pzero, truemotion=truemotion, badSAD=badSAD, badrange=badrange, temporal=temporal,lsad=lsad, lambda=lambda, pglobal=pglobal, plevel=plevel, trymany=trymany, global=sglobal)
bak1 = MAnalyse(superfilt, isb=true, delta=1, blksize=BlkSize, overlap = overlap, search=searchAlgo, searchparam=searchRange, pelsearch=searchRangeFinest, dct=dct, mt=false, scaleCSAD=scaleCSAD, pnew=pnew, pzero=pzero, truemotion=truemotion, badSAD=badSAD, badrange=badrange, temporal=temporal,lsad=lsad, lambda=lambda, pglobal=pglobal, plevel=plevel, trymany=trymany, global=sglobal)
fwd1 = MAnalyse(superfilt, isb=false, delta=1, blksize=BlkSize, overlap = overlap, search=searchAlgo, searchparam=searchRange, pelsearch=searchRangeFinest, dct=dct, mt=false, scaleCSAD=scaleCSAD, pnew=pnew, pzero=pzero, truemotion=truemotion, badSAD=badSAD, badrange=badrange, temporal=temporal,lsad=lsad, lambda=lambda, pglobal=pglobal, plevel=plevel, trymany=trymany, global=sglobal)
fwd2 = MAnalyse(superfilt, isb=false, delta=2, blksize=BlkSize, overlap = overlap, search=searchAlgo, searchparam=searchRange, pelsearch=searchRangeFinest, dct=dct, mt=false, scaleCSAD=scaleCSAD, pnew=pnew, pzero=pzero, truemotion=truemotion, badSAD=badSAD, badrange=badrange, temporal=temporal,lsad=lsad, lambda=lambda, pglobal=pglobal, plevel=plevel, trymany=trymany, global=sglobal)
bak2 = Recalculate ? MRecalculate(superRe, bak2, blksize=BlkSizeR, overlap = overlapR, search=searchAlgoR, searchparam=searchRangeR, dct=dctre, mt=false, scaleCSAD=scaleCSAD, pnew=pnewR, thSAD=thSADR, truemotion=truemotionR, lambda=lambdaR) : bak
bak1 = Recalculate ? MRecalculate(superRe, bak1, blksize=BlkSizeR, overlap = overlapR, search=searchAlgoR, searchparam=searchRangeR, dct=dctre, mt=false, scaleCSAD=scaleCSAD, pnew=pnewR, thSAD=thSADR, truemotion=truemotionR, lambda=lambdaR) : bak
fwd1 = Recalculate ? MRecalculate(superRe, fwd1, blksize=BlkSizeR, overlap = overlapR, search=searchAlgoR, searchparam=searchRangeR, dct=dctre, mt=false, scaleCSAD=scaleCSAD, pnew=pnewR , thSAD=thSADR, truemotion=truemotionR, lambda=lambdaR) : fwd
fwd2 = Recalculate ? MRecalculate(superRe, fwd2, blksize=BlkSizeR, overlap = overlapR, search=searchAlgoR, searchparam=searchRangeR, dct=dctre, mt=false, scaleCSAD=scaleCSAD, pnew=pnewR , thSAD=thSADR, truemotion=truemotionR, lambda=lambdaR) : fwd
C.MDegrain2(superR, bak1, fwd1, bak2, fwd2, thSAD=thSAD, thSADC=thSADC, plane=0, mt=true)
global frame_count = FrameCount()
GMSD(src.ConvertBits(32, fulls=false, fulld=true), ConvertBits(32, fulls=false, fulld=true), show=0)
global total = 0.0
global GMSD = 0.0
global GMSD_total = 0.0
FrameEvaluate(last, """
GMSD = 1.0-propGetFloat("_PlaneGMSD")
global GMSD = (GMSD == 1.0 ? 0.0 : GMSD)
global GMSD_total = GMSD_total + GMSD
""",local=false)
# measure runtime, plugin writes the value to global avstimer variable
global avstimer = 0.0
AvsTimer(frames=1, type=0, total=false, name="Optimizer")
# per frame logging (GMSD, time)
global delimiter = "; "
resultFile = "perFrameResults.txt" # output out1="GMSD: MAX(float)" out2="time: MIN(time) ms" file="perFrameResults.txt"
WriteFile(resultFile, "current_frame", "delimiter", "GMSD", "delimiter", "avstimer")
# write "stop" at the last frame to tell the optimizer that the script has finished
WriteFileIf(resultFile, "current_frame == frame_count-1", """ "stop " """, "GMSD_total", append=true)
#Prefetch(4)
return last
In any case IMO degraining (and most filters by extension) should be a scene based procedure, that's how it's done in big studios like Netflix, etc. They divide the film in scenes and collect metrics for each one (they even encode by scenes). I tried without success to modify StainlessS' ScSelect_HBD() to know beforehand the last and next scene changes so filters can use accumulated per-scene metrics.
__________________
i7-4790K@Stock::GTX 1070] AviSynth+ filters and mods on GitHub + Discussion thread |
|
|
|
|
|
22nd January 2022, 10:14
|
#239 | Link |
|
Pig on the wing
Join Date: Mar 2002
Location: Finland
Posts: 5,731
|
It's often mentioned that dct=5 would be the most optimal choice, so it would be interesting to see how it fares. Also a bigger value for pel seems to change things a lot, at least when viewing things with MShow.
__________________
And if the band you're in starts playing different tunes I'll see you on the dark side of the Moon... |
|
|
|
|
22nd January 2022, 12:14
|
#240 | Link | |
|
Registered User
Join Date: Nov 2009
Posts: 2,361
|
Quote:
A correlation matrix builds a variable x variable sized matrix showing the correlations between them. Simply go to Data -> Data Analysis -> Correlation. I don't think Google Spreadsheets has analysis tools. @Boulder., in my tests results differ a bit whether I'm optimizing for MFlowFPS or MDegrain. For MFlowFPS DCT=1 and pel=2 looks like a no brainer even for 1080p. For MDegrain I found that DCT=0 and DCTR=9 is more optimal, and pel=2 doesn't have a big impact. DCT=5 if any would be more useful for RefineMotion. EDIT: Correlation matrix for 210 random iterations (also in Google Spreadsheets). This (correlation calculation) can work to tune the Sensitivity internals. 
__________________
i7-4790K@Stock::GTX 1070] AviSynth+ filters and mods on GitHub + Discussion thread Last edited by Dogway; 22nd January 2022 at 15:18. |
|
|
|
|
 |
| Thread Tools | Search this Thread |
| Display Modes | |
|
|





 Linear Mode
Linear Mode

