Welcome to Doom9's Forum, THE in-place to be for everyone interested in DVD conversion. Before you start posting please read the forum rules. By posting to this forum you agree to abide by the rules. |
 17th December 2022, 14:58
17th December 2022, 14:58
|
#341 | Link | |
|
Registered User

Join Date: Mar 2021
Location: North Carolina
Posts: 138
|
Quote:
Now, as soon as I went to rd=2 then the quality dropped. So, once I get a chance I'm going to retest on very slow, then just switch the rd setting from 6 to 4 and see what happens. That way most settings are turned on regardless of rd setting, and that way we can see how rd scales properly. However, when encoding Big Buck Bunny even on Medium, resulted in better quality using rd=6 vs rd=4. Which I found interesting. Last edited by HD MOVIE SOURCE; 17th December 2022 at 15:01. |
|

|

|
|
17th December 2022, 16:55
|
#342 | Link |
|
Pig on the wing

Join Date: Mar 2002
Location: Finland
Posts: 5,733
|
Rd 3 and 4 are the exact same, as are 5 and 6. This is stated in the docs.
__________________
And if the band you're in starts playing different tunes I'll see you on the dark side of the Moon... |
|
|
|
|
19th December 2022, 02:15
|
#343 | Link |
|
Moderator
 Join Date: Jan 2006
Location: Portland, OR
Posts: 4,770
|
Yeah. They left some extra room in case they'd want to add intermediate steps in the future.
I'd love to see an --rd 5 which would be "all the stuff from --rd 6 that doesn't mess up with high resolution film grain." |
|
|
|
|
22nd December 2022, 08:35
|
#344 | Link | |
|
shortest name
Join Date: Sep 2022
Posts: 12
|
Quote:
Last edited by A1; 22nd December 2022 at 09:03. |
|
|
|
|
|
9th January 2023, 22:01
|
#345 | Link | |
|
Registered User

Join Date: Jan 2006
Location: Italy
Posts: 260
|
Quote:
This is the first test with Ryzen 9 7950X preset "Slow", I hope that with this upgrade the coding time will be more acceptable. 
Last edited by DMD; 9th January 2023 at 22:08. |
|
|
|
|
|
10th January 2023, 09:09
|
#347 | Link |
|
Registered User
Join Date: Jan 2006
Location: Italy
Posts: 260
|
Yes. You are right, I did not use the same preset.
With "Slower" it is 0.88 fps with the same processor. At this point I think using the "Slow" preset is a good compromise between performance and final quality, I don't nthink "Slower" significantly affects the quality. If I haven't miscalculated, an estimated process difference of about 37h40min between the two presets, is that much time difference worth it? Example: 2 hours of movie @24fps 0.88fps>55h 2.75fps>17h 45min 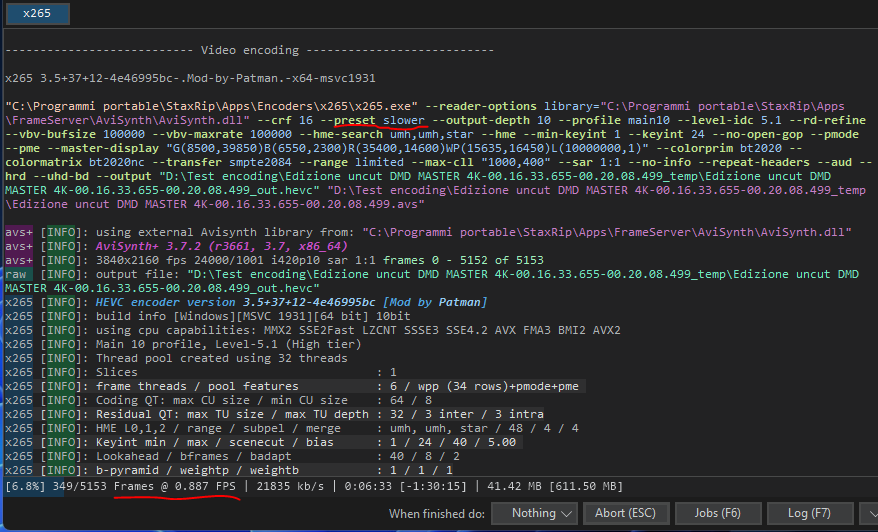
Last edited by DMD; 10th January 2023 at 10:04. |
|
|
|
|
10th January 2023, 16:43
|
#348 | Link | |
|
Moderator
Join Date: Jan 2006
Location: Portland, OR
Posts: 4,770
|
Quote:
Apples-to-apples comparisons can't rely on just presets, however. The number of frame threads can have a big impact on perf and a smaller impact on quality, and the default number of frame threads is based on how many cores are available. Thus comparing two processors with different core counts can see the processor with more cores running with more frame threads, improving encoding speed but potentially reducing quality. So not quite apples-to-apples. Benchmarking is hard to do in a broadly applicable way, because there are so many encoding scenarios that can impact relative performance. Comparing at slow with default frame threads is certainly a scenario that will matter to plenty of people. For me, comparing with --preset slower --frame-threads 1 would have the most relevance. Benchmarking for realtime encoding would be very different, as predictable worst-case encoding time becomes essential. Plenty of benchmarks just compare with stock default settings. I see you are comparing with --pmode (makes good sense if you have a lot of cores relative to frame size, but can slow things down if there aren't enough cores) and --pme (which is a net negative unless you have a whole lot of cores encoding sub-HD resolutions). I consider it "fair" to use --pmode if it is only used when it increases throughput in a given configuration, and turned off when it doesn't. As --pmode doesn't decrease quality (and can theoretically increase it a bit). The same can apply to using --pme selectively, although the cores needed to make it a net positive are a lot higher. But for 480p with 64 cores or something, it probably would help. I personally rarely test with more than 18/36 available for any given encoder instance. Although with all the ARM patches, Graviton2/3 with 64 cores deserves some benchmarking as well. |
|
|
|
|
|
11th January 2023, 12:43
|
#349 | Link | |
|
Registered User
Join Date: Jan 2006
Location: Italy
Posts: 260
|
Quote:
|
|
|
|
|
|
12th January 2023, 00:37
|
#350 | Link | |
|
Moderator
Join Date: Jan 2006
Location: Portland, OR
Posts: 4,770
|
Quote:
First rule is to define as specific a question as possible, and then figure out the optimal benchmarking approach for that. |
|
|
|
|
|
8th February 2023, 20:19
|
#351 | Link | |
|
Registered User
Join Date: Jul 2018
Posts: 1,070
|
Quote:
It looks 'auto' asm is still up to AVX2 and AVX512 still need to be enabled manually. Also for getting more performance of software_for_task at different architectures it is better to use optimized builds for each architecture (making equal output work). In other case it is mostly testing different architectures for executing some single build of software (may be not optimal to any of tested architectures). About AVX512 capable chips and x265 usage: 1. It may be better to use build for AVX512 architecture executable. May be better to use Intel C compiler mastered by Intel for 10+ years for AVX512 architecture even for AMD AVX512-compatible chips. Also having all-project (multi-file) interprocedural optimization features. When compiler build for selected architecture it can use additional features like larger register file for params storage and special instructions. The disadvantage - the executable can only run at the target (or higher compatible) chip and will cause 'illegal instruction' crash at lower architectures. So for users of AVX512 chips it may be better to found or ask developers or self build the AVX512-targeted build for work. So 'universal' run-about-everywhere like from SSE2 and higher architectures builds of x265 are not optimized for AVX512 architecture by compiler (and may have degraded performance). 2. In the 'old' github sources from 2020 https://github.com/videolan/x265 usage of optional handcrafted AVX512 codepaths is not enabled by default options set. So it must be activated by command line option --asm avx512 (also may be good to found all other SIMD string options somewhere). May be it is the same for newer versions for https://bitbucket.org/multicoreware/...?tab=downloads site. |
|
|
|
|
|
10th February 2023, 22:47
|
#352 | Link | |||||
|
Moderator
Join Date: Jan 2006
Location: Portland, OR
Posts: 4,770
|
Quote:
Quote:
Quote:
Quote:
Quote:
--asm <integer:false:string>, --no-asm Last edited by benwaggoner; 13th February 2023 at 21:30. Reason: Fixed quoting |
|||||
|
|
|
|
11th February 2023, 01:28
|
#353 | Link |
|
Registered User
Join Date: Jul 2018
Posts: 1,070
|
"This is because using AVX512 causes a net performance decrease in almost all x265 use cases."
I make quick test with my build with VisualStudio 2019 sources from github - at i5-11600 intel chip enabling AVX512 with command line option give about 4.8% benefit with FullHD encoding with --placebo profile over 'auto' SIMD. But it may be rare intel chip without frequency decrease at AVX512 usage. (low core number - only 6 cores). |
|
|
|
|
11th February 2023, 20:16
|
#354 | Link | |
|
Big Bit Savings Now !

Join Date: Feb 2007
Location: close to the wall
Posts: 1,545
|
An i9-11900K sees AVX-512 profit too here, I guess I can bind that to the production node of Rocket Lake.
Quote:
These 14nm chips seem to be able to pull through that workload without too much thermal penalty. (as the predecessors did) Until AVX-512 got to be fixed/tucked/fused away for the following families by Intel themselves, as I heard...
__________________
"To bypass shortcuts and find suffering...is called QUALity" (Die toten Augen von Friedrichshain) "Data reduction ? Yep, Sir. We're that issue working on. Synce invntoin uf lingöage..." Last edited by Emulgator; 11th February 2023 at 20:24. |
|
|
|
|
|
12th February 2023, 04:28
|
#355 | Link |
|
Moderator
Join Date: Jan 2006
Location: Portland, OR
Posts: 4,770
|
Exciting news! Too bad the latest Intel consumer chips dropped AVX512. Comparing with CPU-specific and profile-driven optimizations would be neat to see. And now we have quite a bit of ARM SIMD and some good ARM performance CPUs in Macs and Graviton, we can compare architectures too.
|
|
|
|
|
13th February 2023, 10:34
|
#356 | Link |
|
Registered User
Join Date: Oct 2001
Posts: 454
|
I wonder how one of the later x64 compatible Xeon PHI would perform with x265. The cores themselfes where weaker atom cores, but if I recall correctly, they had a bunch of AVX512 features already on board and up to 64 cores per "CPU", often hosting 4 CPUs in one server (and 4 x hyperthreading), giving an insane number of 256 Threads per CPU, 1024 for one complete Server... If something like ripbot would distribute the encoding over the cores, cleverly avoiding too much bottlenecking between ram-swapping.. Might be interesting
 I know that the cores themslelfes are way behing what modern cores could do - but if "the rest" of the core is enough to feed the AVX512 unit efficiently, maybe the number of cores makes up for the lack of frequency and cache ? |
|
|
|
|
13th February 2023, 21:35
|
#357 | Link | |
|
Moderator
Join Date: Jan 2006
Location: Portland, OR
Posts: 4,770
|
Quote:
I expect the Atom cores would bottleneck on CABAC pretty hard. Some kind of hybrid NUMA approach with some performance cores and slower-but-SIMD cores could work. The key to a hybrid model like that would be low-latency access to shared L3 cache. That kind of mixed-core architecture is becoming pretty standard. |
|
|
|
|
|
14th February 2023, 18:26
|
#358 | Link | |
|
Registered User
Join Date: Feb 2023
Posts: 5
|
Quote:
I generally use a 5950X (16 core/32 thread) for encoding and find that using H.265 10-bit on 4K sources winds up with 90+% CPU utilization at Slow-Slower-Very Slow presets. On BD sources, CPU utilization is more in the 40-50% range. I have tried applying pmode in Handbrake (pmode=1) and found it to only be beneficial with BD encodes at Very Slow preset. In testing with three movies at RF 19, Very Slow, pmode=1 reduces encode time 15-20% and increases CPU utilization roughly 20%. The output files with pmode=1 are generally slightly smaller than an encode with same settings and no options. One movie, somewhat grainy, showed a significant size reduction - 4247 MB with no options and 3474 MB with the pmode=1 option. I repeated this encode and confirmed the results. FWIW - No option took 13:46 (hours:minutes) to encode and pmode=1 took 10:31 to encode. Based on what I'd read here, I wasn't expecting significant size change from pmode....wondering about any thoughts from experts..?? |
|
|
|
|
|
17th February 2023, 16:07
|
#360 | Link | |
|
Registered User
Join Date: Oct 2001
Posts: 454
|
Quote:
The atom cores on these later Xeon PHi indeed are pretty weak in integer and floating point. They do have a 16GB internal Cache though which is accessable by all the cores - maybe that helps. But I just checked, the widely available nights Landing Chips only offer a very small subset of AVX 512 Instructions, only the latest ones have a few more modern subsets on board. Is there any ressource to x265 where the used AVX512 modi are listed? |
|
|
|
|
 |
|
|






 Linear Mode
Linear Mode

