Welcome to Doom9's Forum, THE in-place to be for everyone interested in DVD conversion. Before you start posting please read the forum rules. By posting to this forum you agree to abide by the rules. |
 8th December 2021, 14:03
8th December 2021, 14:03
|
#761 | Link |
|
Registered User
Join Date: Nov 2009
Posts: 2,361
|
I'm talking about future future but Intel chips will start to make sense again after Meteor Lake, but personally will wait until Luna or Nova Lake, when new tech like big-little, TDP and DDR5 issues (and prices!) settle down. In any case I don't think heat issues will improve so I see myself switching from my current 140mm rad to a 280mm one.
__________________
i7-4790K@Stock::GTX 1070] AviSynth+ filters and mods on GitHub + Discussion thread |

|

|
|
8th December 2021, 15:33
|
#762 | Link |
|
Registered User
Join Date: Jul 2018
Posts: 1,070
|
In the future future I think it is good to make 'auto-degrain' version with some preset output target SNR. And auto-adjustment of tr and thSAD values to reach this preset output target SNR.
We have everyday lots of different footages with different camera gain settings so even with about equal cameras the relative noise levels still very different from outdoor shootings with good lighting and low gain and noise to indoor opera/balet show with poor lighting and high relative noise levels from raised gain at cameras. So to use large tr and thSAD values for worst noise will take more time and degrade quality at low noise footages. Some automation required. Like statistical analysis of medium/average SAD coming from MAnalyse and backward adjusting of tr and thSAD from MDegrainN. |
|
|
|
|
8th December 2021, 17:20
|
#763 | Link | ||||
|
Acid fr0g

Join Date: May 2002
Location: Italy
Posts: 2,580
|
Quote:
Quote:
 Quote:
Quote:
__________________
@turment on Telegram |
||||
|
|
|
|
8th December 2021, 17:57
|
#764 | Link |
|
Registered User
Join Date: Nov 2009
Posts: 2,361
|
I have thought on adding some auto-tune algo, based on variance or stdev, but it implies sampling a portion of the clip and I don't know how user friendly that would be.
If you offhand the portion sampling to the filter it will spend most of the time trying to find a "flat" area to sample and yet it would fail based on luminance based grain. Maybe the first option might be better, there are many estimators so it's a matter of finding one that works nice with SAD. SAD is a simple L1-norm if I'm not mistaken. I will run some tests. EDIT: test Code:
# 8-bit input
Crop(1278, 0, -462, -868)
a=ex_median("IQM5")
# 5x5 block SAD
SAD = Expr(last,a,"
x[-2,-2] y[-2,-2] - abs x[-1,-2] y[-1,-2] - abs x[0,-2] y[0,-2] - abs x[1,-2] y[1,-2] - abs x[2,-2] y[2,-2] - abs
x[-2,-1] y[-2,-1] - abs x[-1,-1] y[-1,-1] - abs x[0,-1] y[0,-1] - abs x[1,-1] y[1,-1] - abs x[2,-1] y[2,-1] - abs
x[-2,0] y[-2,0] - abs x[-1,0] y[-1,0] - abs x[0,0] y[0,0] - abs x[1,0] y[1,0] - abs x[2,0] y[2,0] - abs
x[-2,1] y[-2,1] - abs x[-1,1] y[-1,1] - abs x[0,1] y[0,1] - abs x[1,1] y[1,1] - abs x[2,1] y[2,1] - abs
x[-2,2] y[-2,2] - abs x[-1,2] y[-1,2] - abs x[0,2] y[0,2] - abs x[1,2] y[1,2] - abs x[2,2] y[2,2] - abs
+ + + + + + + + + + + + + + + + + + + + + + + +
","")
ScriptClip( function[a, SAD] () {
str = AverageLuma(SAD)*5
subtitle(string(str)) } )
__________________
i7-4790K@Stock::GTX 1070] AviSynth+ filters and mods on GitHub + Discussion thread Last edited by Dogway; 8th December 2021 at 19:58. |
|
|
|
|
8th December 2021, 18:59
|
#765 | Link |
|
Registered User
Join Date: Jul 2018
Posts: 1,070
|
"test shows that AVX512 work only when E-cores are disabled, at least for Alder Lake."
It looks Microsoft was not ready to such hybrid chips and still no official threading API to support thread signaling if it use some instructions set and to chip Threads Planner to use this data and not allow some threads to be switched to non-supported core and crash. So it either all active cores use AVX512 or application will crash when Thread Planner will occasionally switch it to E-core. "Is there any chance you will port MVTools to CUDA, Vulkan or OpenCL?" There is already some version of CUDA-based processing. I do not have fast GPUs of CUDA-capable. That versions may be limited in max tr value ? Or only fixed to MDegrain1,2,3, ? In the very theory I think about distributed processing of MAnalyse with workers based on any hardware (CPU/GPU/ASIC etc) but it still not help to the MDegrainN that is not very fast curently too. And to put MDegrainN do GPU with all frame processing it looks required too much of onboard memory (it scan via 2*tr ref frames for each output frame, for tr=30 and UHD 8Msamples frame with pel=1 it is about 1.5 GBytes memory minimum, the current tr max is 128). MAnalyse only scan via current and 1 ref frame for each call of MDegrainN GetFrame() so each src-ref pair may be offloaded to small enough worker. Anyway it is too much redesign and I not any good C programmer - I can only make simple C programs and assembler. Nowdays as Microsoft disables inline asm in x64 programs it is intrinsics-based. Some known issue about intrinsics based program - https://stackoverflow.com/questions/...61394#70261394 . So it will more or less depend on compiler and need to make it compatible with many compilers and select the best by speed of output executable. "# 5x5 block SAD" In the MShow it can be switched showsad to 'true' - Allows to show the mean (scaled to block 8x8) SAD after compensating the picture I think its value is good correlated with the SNR. With script: Code:
LoadPlugin("mvtools2.dll")
LoadPlugin("AddGrainC.dll")
ColorBarsHD(1920,1080)
AddGrain(0)
Trim(0,250)
super = MSuper (pel=1)
forward_vec1 = MAnalyse(super, isb = false, search=3, searchparam=2, chroma=false, delta = 1, mt=false)
MShow(super,forward_vec1, showsad=true)
addgrain=1 sad=68 addgrain=2 sad=96 addgrain=4 sad=136 addgrain=8 sad=191 addgrain=16 sad=271 "do proper versions without having to put hand to the AVSI I use" Here is 2 tests (with that latest .dlls with PT4 for possibly fastest speed of MAnalyse to look at MDegrainN raw speed): Code:
LoadPlugin("mvtools2_asb16_ivc_SO1_PT4.dll")
ColorBarsHD(1920,1080)
Trim(0,1000)
tr = 12 # Temporal radius
super = MSuper (pel=1, hpad=64, vpad=64)
multi_vec = MAnalyse (super, multi=true, blksize=64, blksizeV=16, delta=tr,chroma=false,mt=false, levels=2)
MDegrainN (super, multi_vec, tr, thSAD=300, thSAD2=300-1, mt=false)
Prefetch(2)
Code:
LoadPlugin("mvtools2_asb16_ivc_SO1_PT4.dll")
ColorBarsHD(1920,1080)
Trim(0,1000)
tr = 12 # Temporal radius
super = MSuper (pel=1, hpad=64, vpad=64)
multi_vec = MAnalyse (super, multi=true, blksize=16, blksizeV=64, delta=tr,chroma=false,mt=false, levels=2)
MDegrainN (super, multi_vec, tr, thSAD=300, thSAD2=300-1, mt=false)
Prefetch(2)
Last edited by DTL; 8th December 2021 at 21:22. |
|
|
|
|
8th December 2021, 21:26
|
#766 | Link | ||||
|
Acid fr0g
Join Date: May 2002
Location: Italy
Posts: 2,580
|
Quote:
Quote:
Quote:
Quote:
__________________
@turment on Telegram |
||||
|
|
|
|
8th December 2021, 22:20
|
#767 | Link | ||
|
Broadcast Encoder

Join Date: Nov 2013
Location: Royal Borough of Kensington & Chelsea, UK
Posts: 2,904
|
Quote:
A couple of other questions: - do you think we will ever get to a point in which compilers will be smart enough to generate fast enough code automatically at compile time while targeting an instruction set so that manually written intrinsics won't be necessary/worth writing or will it ever be science fiction? - with the increasing number of high level languages and many young programmers taking the short route and using rust, python, electron, etc do you think there's gonna be a drop in performance in the near future as less and less people will be able to code in C++, let alone write instrinsics in assembly? Quote:
|
||
|
|
|
|
8th December 2021, 22:54
|
#768 | Link | |
|
...?

Join Date: Nov 2005
Location: Florida
Posts: 1,420
|
Quote:
Inline assembly is using the actual assembly code syntax itself, inside the code. It's usually compiler-specific as well, at least to a certain degree. Stuff like NASM assembly probably doesn't count, as even though it does go down to the base commands, it's slid in externally and parsed by a dedicated program. Some inline assembly does still exist in the AviSynth+ sources, like this block in PluginManager.cpp (which, because of how this works, can only be used when building with MSVC for 32-bit): https://github.com/AviSynth/AviSynth...ager.cpp#L1210 Intrinsics, on the other hand, are largely compiler-provided shortcuts to the CPU's SIMD instructions that are able to be used more like regular C/C++, as keywords when the code needs to target particular instructions. For example, here in focus_sse.cpp: https://github.com/AviSynth/AviSynth...s_sse.cpp#L157 All those __m128i and _mm_**_** calls? Those are the intrinsics. Runtime dispatch of a particular feature set doesn't have anything to do with inline asm vs. intrinsics; that's purely on either the compiler or the programmer setting up dispatching correctly. If a SIMD instruction your CPU doesn't support gets through, the program will crash with a SIGILL when you try to run it. How compilers treat the regular C/C++ code can factor into this as well: if the compiler was told to optimize everything for an instruction set your CPU doesn't support, it'll translate the compiled C/C++ code into SIMD that doesn't exist on that CPU, and you'll get a SIGILL (this isn't as much of a problem with MSVC, but it can be a big one with GCC). Generally, this is why Release builds of just about anything don't have myriad different builds compiled for every permutation of CPU out there: the plain code was left with the general optimizations the compiler can do but not any SIMD translation, and any inline asm or intrinsics are only active under codepaths it can detect are needed. Or at best, there's a baseline minimum CPU the plain code gets optimized for (one example would be FFMS2 and the whole thing over -msse/-march=pentium3 or -msse2 on 32-bit builds). |
|
|
|
|
|
8th December 2021, 23:42
|
#769 | Link |
|
Registered User
Join Date: Jul 2018
Posts: 1,070
|
"I think it's Intel side. Alder Lake has the same architecture of Xeon ones and they do support AVX512."
I do not think Xeons have hybrid of different cores with different instructions sets. I think Adler Lake is the first chip with this design. And it require special software support. "You mean SVP? AFAIK it's paid and really limited." I see that thread - https://forum.doom9.org/showthread.php?t=183476 it is about SVSuper and SVAnalyse and uses GPU ? Also pinterf point to some project - https://github.com/pinterf/AviSynthC...e/master/KTGMC . "What's the difference between inline assembly and manually written intrinsics? " Intrinsincs is semi-asm semi-C. Mostly special C operators more or less mapped to 'real' hardware CPU instructions (also containing many 'virtual' macros that is a sequences of instructions more or less on the compiler decision). One of the possible issue - it do not have method of pointing to memory operand where avaialble (currently). So if compiler fail to understand programmer's idea it is only possible to send complain to compiler's designer and waiting to next patched release if possible. Or write separate asm file to the project manually. "you can tell which instructions set to use dynamically while with inline assembly you can't and it would just fail if you try to execute a program which has AVX2 in a CPU that supports SSE4.2?" No. With intrinsics programmer must design separate functions for each large-vector co-processor type (SSE2/AVX2/AVX512 and future). Instructions sets between different large-vector co-processors are not compatible. "- do you think we will ever get to a point in which compilers will be smart enough to generate fast enough code automatically at compile time while targeting an instruction set so that manually written intrinsics won't be necessary/worth writing or will it ever be science fiction?" No. Each hardware SIMD large-vector co-processor architecture require special and separated design of program and they are not completely 'expandable' between different SIMD families and generations. They even do not inherit instructions sets completely with advances of generations - SSE have unique minpos() instruction and in it 128bit SSE4.1 only. Not exist in the next AVX2 and AVX512 and looks like not any replacing. So after SAD calculation in AVX2 or AVX512 instructions it is required to go down to 128bit SSE and use minpos() to found where is the min SAD positioned. It still faster in compare with going to 'general purpose core' and use loop with compare-based search for minimum member of vector. And SkyLake and possibly newer chips have 3 execution ports for minpos() instruction so after 4 clocktics latency it can output 3 minpos results per clock. AVX2 256bit have mpsadbw() that not propagated to AVX512 and as I see the dbsadbw() in AVX512 can not be used as complete replacing. mpsadbw can be used for search up to sp3 full positions and sp3.5 with reduced 1 column. And dbsadbw only for sp1 (and for larger sp with data shift/reloading but it is a performance penalty). So the already created program design can not be easily ported to next generation of large-vector co-processor. So the 'AVX512' search function is actually mix of different instructions sets down to SSE. Fortunately chips are still backward-compatible and AVX512 chip can execute SSE instructions though there is some penalty of going down from 512bit vectors to 128bit and back. "- with the increasing number of high level languages and many young programmers taking the short route and using rust, python, electron, etc do you think there's gonna be a drop in performance in the near future as less and less people will be able to code in C++, let alone write instrinsics in assembly?" It need to be separated 'general purpose Computer usage' and 'special data processing'. The general purpose computer usage is enough serviced by any high level programming language and general purpose CPU part of core. The special data processing is typically usage of special SIMD co-processor. The SIMD large-vector co-processor is highly integrated in general purpose CPU core but still have its special instructions set (and limited in operations) and separated register file (different size and 'word width' for each family). Any compiler with knowledge about its presence can use its register file for some temporal storage or even some data processing. And unlikely will be any compilers from 'general purpose' high level programming languages to SIMD co-processor (intel promises for 'auto-parallelization' where possible and where available but it still require too much preparation work from programmer). Because it is special purpose processing engine and not compatible with typical high level programming language. Though the intrinsics support can be made to any high level compiler. In theory it is possible to make special compiler for auto-creating designs for different SIMD co-processors but it is sort of the far future and the number of useful tasks will be still very limited. Mostly real is special libraries of functions designed for selected SIMD co-processor family. Last edited by DTL; 8th December 2021 at 23:48. |
|
|
|
|
8th December 2021, 23:51
|
#770 | Link | |
|
Acid fr0g
Join Date: May 2002
Location: Italy
Posts: 2,580
|
Quote:
Would you please explain me the differences between each search options and parameter options? I saw you compiled plain version, search option 1 and SO1 plus parameter 4. How are them different, speed and quality wise?
__________________
@turment on Telegram |
|
|
|
|
|
9th December 2021, 00:01
|
#771 | Link |
|
Registered User
Join Date: Jul 2018
Posts: 1,070
|
"plain version, search option 1 and SO1 plus parameter 4. How are them different, speed and quality wise?"
Plain is controlled by parameters optSearchOption(0,1) and optPredictorType(0,1,2,4). SO1 is hardcoded optSearchOption=1 - it should be like you tested + fixed bug with skipping some predictors. Full quality (default PredictorType=0). SO1_PT4 - is hardcoded optSearchOption=1 optPredictorType=4. It is special demo of 'logical optimization' - skipping level 0 processing and output interpolated (scattered to 4 larger buffer positions) prediction from level 1 (other levels uses PT=0 - full predictors). It should be fastest but quality may be more or less degrade depending on content. May be it will be useful for 'drafting' work or other. Require lowering thSAD value at MDegrain (I hope it is controlled in the typical script functions params) to about 1.5 times lower in compare with 'standard'. " I dunno if it will have E-cores too." I think Xeon customers are not interested in paying thousands for low-performance Effective cores. And re-design software to use mixed cores chip. Last edited by DTL; 9th December 2021 at 00:05. |
|
|
|
|
9th December 2021, 00:05
|
#772 | Link | ||
|
Acid fr0g
Join Date: May 2002
Location: Italy
Posts: 2,580
|
Quote:
Quote:
__________________
@turment on Telegram |
||
|
|
|
|
9th December 2021, 00:07
|
#773 | Link |
|
Registered User
Join Date: Jul 2018
Posts: 1,070
|
"Quality wise, is it better, worse or on par with stable?"
It should be very close. "double SMDegrain calls, on the first one." Yes - may be good example. But you can not mix different .dlls with equal functions names in 1 script. To use PT4 in one script it is required to load 'universal options-controlled .dll' and set param optPredictorType=4 to the draft MAnalyse(). Last edited by DTL; 9th December 2021 at 00:12. |
|
|
|
|
9th December 2021, 11:04
|
#774 | Link | |
|
Acid fr0g
Join Date: May 2002
Location: Italy
Posts: 2,580
|
Quote:
__________________
@turment on Telegram |
|
|
|
|
|
9th December 2021, 16:11
|
#775 | Link |
|
Registered User
Join Date: Jul 2018
Posts: 1,070
|
Some not very great about AVX-512 in Adler Lake - https://www.anandtech.com/show/17047...d-complexity/2
Though speedbonus of AVX-512 if correctly used by software is about 3..4x over the old chips. Last edited by DTL; 9th December 2021 at 16:24. |
|
|
|
|
11th December 2021, 00:02
|
#776 | Link |
|
Registered User
Join Date: Jul 2018
Posts: 1,070
|
Some fresh info about first testing of SO3 (4 blocks 8x8 AVX2 processing) and SO4 (16 blocks 8x8 AVX512 processing) on
1. i5-11600 (2 DIMMs single sided (1 ranks) installed, possibly 2 channels) 2. Xeon Gold 6134 (all 6 memory channels should be installed in HP workstation) Current results: 1. i5-11600 in raw MAnalyse performance (MDegrain rows processing close to disabled - only 1 st column left) about 2 times slower in best case (195 vs 104 fps). 2. SO3 4 blocks AVX2 processing in current testbuild a bit better at Xeon and a bit slower at i5-11600 in compare with AVX512 16 blocks processing. It looks even 4 blocks AVX2 processing takes all available memory bandwidth. And task still severily memory bound. 3. SO3 at Xeon (with 6 memory channels) is about 60% faster SO2 (1 block SIMD search). At i5-11600 - about 40% faster. 4. Some simple attempt of prefetching source blocks (about +3..+4 groups of blocks in advance) at all systems make a bit better performance (about 2..3%) so it is good to adjust manual prefetches. The hardware prefetchers not completely nice. And it also points to severe memory speed bounding of task. 5. At Xeon 8cores and 16 Hyperthreading switching from 8 to 16 threads good adds performance - about 40%. At i5-11600 8 cores 16 Hyperthreading - switching from 8 to 16 threads almost change nothing (may be 2 single rank DIMMs in 2 channels too low in speed to use > 8 threads). So todo list: 1. Finish debug SO3 first. 2. Try to re-write MDegrainN processing to lines-based for the total frame width scan instead of current blocks-based. And test its speed difference. |
|
|
|
|
28th December 2021, 10:55
|
#777 | Link |
|
Registered User
Join Date: Jul 2018
Posts: 1,070
|
"Is there any chance you will port MVTools to CUDA, Vulkan or OpenCL? Than would help a lot more and nowadays it's much more widespread to have a fast GPU than the latest CPU."
It looks we come to the limit of current architecture of 'triplet' MDegrainN + Avisynth-API + MAnalyse. It uses frames memory management by Avisynth and in host-CPU memory. It is working with host-CPU for MAnalyse but not effective with ME-engine on separate HW-accelerator board. With current architecture to create MVs for N output frames of N MDegrain threads it is require to upload to HWAcc board in worst case (2_x_tr)_x_2 x_N frames. With partial optimization of keeping Src resource reference for all calls to MAnalyse it can be lowered to (2_x_tr)_x_N . But with full optimization with resource management in HWacc board by one coordinator process it will be close to N only. So in best case we need to ask Avisynth core developers to add HWAcc frames memory management so any filter in the Avisynth environment can only point to the resource ID (frame buffer) already loaded to HWAcc memory instead of re-uploading it every time. I see in DeviceManager.cpp of Avisynth something about CUDA, but current ME-API from Microsoft is based on DirectX-graphics API resources operation (upload/download to DirectX/GPU-domain and interfacing with ME-engine). It is less specific of HW manufacturer but still specific for Windows OS and also not Linux/UNIX compatible (directly, may be wine ?). The current may be easy to implement solutions may be: 1. Make DX12-ME option for MAnalyse to be compatible with all other filters of MVtools but it will be most ineffective with data transfer speed to HWAcc. 2. Make separate version of MDegrain(X/N) with direct interfacing with DX12-ME and working without MAnalyse. It will have its own tracking of loaded to HWAcc resources (frames) and decrease upload traffic. It is still not compatible with AVS-MT nicely because each instance of MDegrain(X/N) will create its own pool of uploaded frames to HWAcc and it is also not best way. 3. Make again internal MT MDegrain(X/N) using existing avstp.dll (cured from freezing) or some other MT. It can manage its single pool of uploaded to HWAcc frames and use all host CPU cores for degraining processing. It may be not best solution for large processing scripts using AVS-MT ? Is it possible to run only one instance of MDegrainN in AVS-MT environment and many other filters ? Current data flow in DX12-ME processing with ME engine in HW video encoder: 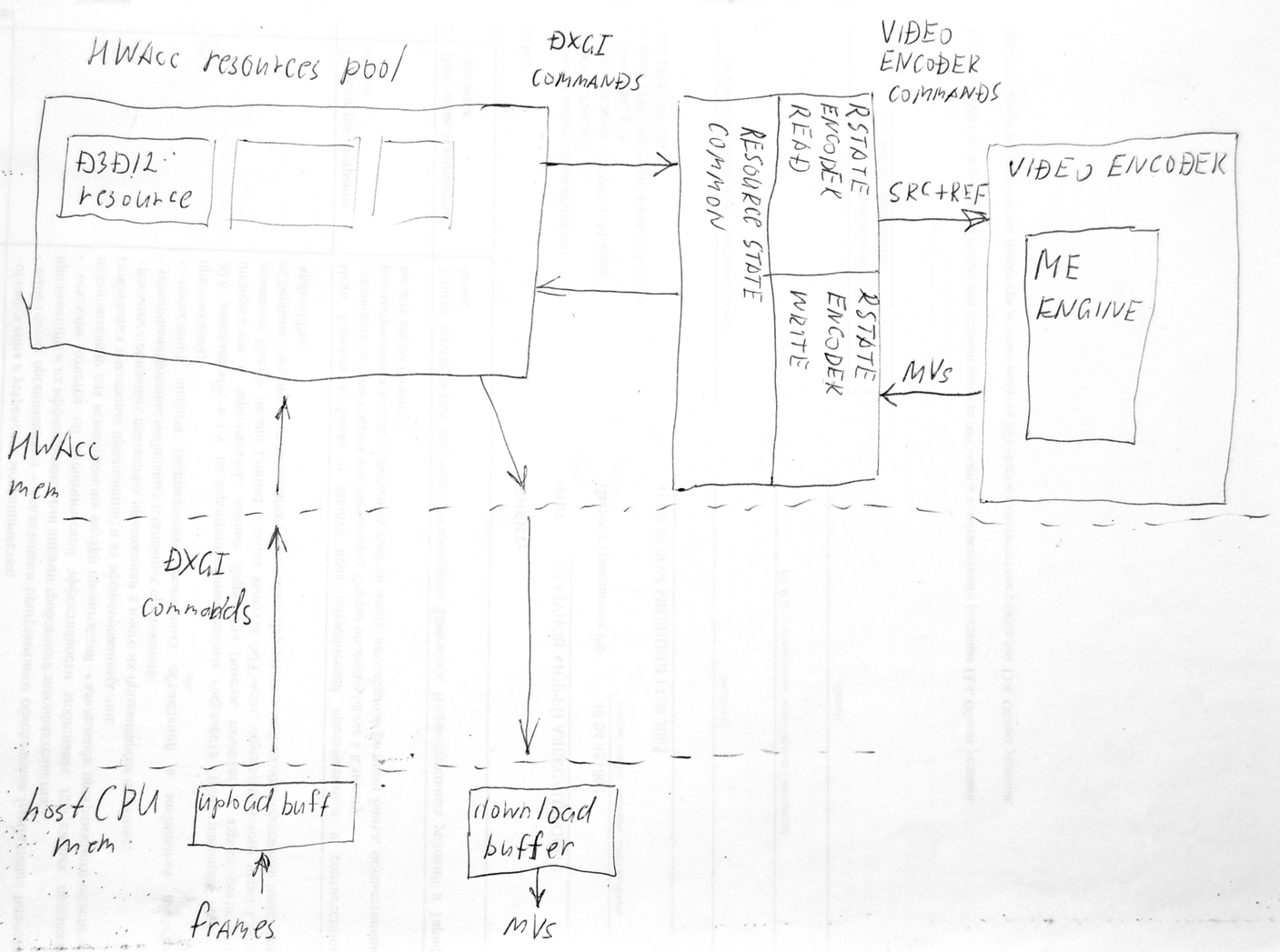
Last edited by DTL; 28th December 2021 at 11:18. |
|
|
|
|
1st February 2022, 11:30
|
#778 | Link |
|
Registered User
Join Date: Jul 2018
Posts: 1,070
|
Make design idea how to make pel=2 and pel=4 processing faster:
In the old days the CPUs were slow and for sub-pel processing MSuper create 4x for pel=2 and 16x for pel=4 sub-shifted copies of input frame and the special GetBlock(x,y) function returns pointer to the sub-shifted full size sub-plane. This cause increasing read memory to 4x and 16x for pel 2 and 4. But close to zero CPU load for getting sub-shifted ref block for processing. Todays CPUs much faster in computing and todays PC architecture still very slow in host RAM speed and its latency and caches sizes are too low to fit so many buffers. So is an idea - to make sub-shifting of ref block 'on-request'. So simply add +1 block-sized buffer to MAnalyse and MDegrain 'workspace' and modify GetBlock(x,y) function to create sub-shifted block from single full-sized ref plane and return pointer to temp buf of this sub-shifted ref block. It will not be compatible with optSearchOption > 1 of Manalyse many search functions (for now it will increase search radius from 2 to 4 for pel=2 and only radius=4 SIMD search may be used - larger still not created but possible with AVX512). Need an idea how to control this from mvtools params. In best way it should started from MSuper() - not create sub-shifted planes at all but send bit-flag of 'new pel' processing to Manalyse and Mdegrain. May be encode it as a bitfield in nPel value (currently it is 1 or 2 or 4) it is 0,1,2 bits set. So may be set 3rd bit to indicate 'new pel' processing ? |
|
|
|
|
1st February 2022, 16:34
|
#779 | Link | |
|
Acid fr0g
Join Date: May 2002
Location: Italy
Posts: 2,580
|
Quote:
Just my 2 cents. 
__________________
@turment on Telegram |
|
|
|
|
|
1st February 2022, 19:28
|
#780 | Link |
|
Registered User
Join Date: Jul 2018
Posts: 1,070
|
"a way to introduce HBD support."
DX12_ME API currently do not support anything but NV12 for MVs search input. And it 8bit YV12 format. The MDegrainN is support any old mvtools2 (the only float looks like broken somewhere but I think noone use it) inputs that 16bit also. Current main sad limit - no overlap support with DX12_ME only search (may be overlap may be added with additional MRecalculate() before MDegrainN - but it will make processing slower and may remove most of benefit of DX12_ME pel up to 4 speed). The DirectX/DirectCompute can have full functions of onCPU mvtools but may be in some future. Currently only 1 of 3 tasks is in active development - the SAD calculating on DirectCompute-ComputeShader because it not exist with DX12_ME output. The MVs search (including overlap mode) and MDegrainN is still for future. It may not give very large speedup for me - my system with i5-9600K CPU still very slow with x264 encoding. So with full degraining offload to accelerator I will got only about 2x total transcoding speed. Currently with pel=4 ME engine load is about 30% only and I mostly interesting in putting its resources to help x264 in speed - see https://forum.doom9.org/showthread.p...23#post1962723 . About pure onCPU pel>1 we have big field of new SIMD functions: 1. Sub-shift to temp buf in RAM(cache) and feeding separate search functiion. (For each pel, block size) 2. Load src + ref blocks in register file and perform sub-shift + search in register file only (require to load interpolation kernel in register file too). It looks only possible with AVX2 or better AVX512 register file even for small 8x8 block. Last edited by DTL; 1st February 2022 at 22:57. |
|
|
|
 |
|
|



 Linear Mode
Linear Mode

