Welcome to Doom9's Forum, THE in-place to be for everyone interested in DVD conversion. Before you start posting please read the forum rules. By posting to this forum you agree to abide by the rules. |
 4th May 2021, 19:04
4th May 2021, 19:04
|
#21 | Link | |
|
Registered User
Join Date: Sep 2007
Posts: 5,377
|
Quote:
Occlusions/FG/BG layers - those are one of the common failings with mvtools2 (and many other optical flow approaches) - I've posted about this before in other threads in more detail. Masking and using blends like FRC's approach might make it less jarring when watching normally, but blended rings/halos and textures don't look that great either. My "go to" for the some of the problem scenarios (especially the 3 listed in the previous post) is RIFE, with some clean up in other programs. The edge quality alone is worth it. Even if it "fails" in other areas, when you combine/composite approaches, you can get a usuable solve with muchs work. Here are some apng demos highlighting edge quality of occlusions, FG objects on Mark's clip. I've brightened up the 2nd one. RIFE used jm_fps to bring it from 47.952=>59.94 . So the RIFE result is still "exposed" to mvtools2, but since the object and "frame samples" are closer at 47.952, the 2nd mvtools2 interpolation is cleaner, than if it had to do the full 23.976=>59.94. The clip Mark uploaded was a lower quality re-encode, the edges should be cleaner if the original video was used The apng's in the zip archive should animate in most browsers, just open up in a tab https://www.mediafire.com/file/55znm..._apng.zip/file Another "negative" to DAIN/RIFE is built in scene detection is quite poor compared to mvtools2 based scripts. It would be nice to have native RIFE vapoursynth implementation with built in scene detection |
|

|

|
|
4th May 2021, 23:20
|
#22 | Link | ||||||
|
Registered User
Join Date: Mar 2018
Posts: 447
|
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
|
||||||
|
|
|
|
5th May 2021, 01:58
|
#23 | Link | |||
|
Registered User
Join Date: Sep 2007
Posts: 5,377
|
Quote:
Lets see if any combinations can help in some of these tricky situations. But I have a feeling that no settings will help much for the occlusions, moving object boundaries on a "picket fence" type background scenario Quote:
eg. RIFE "failed" in the 2nd scene on the right side of the frame, where jm_fps breezed through without much issues. You have to combine results to get optimal results. I don't expect mvtools2 to work best with 1 set of settings on different types of characteristics either, or denosing with 1 set of settings on different types of noise across different scenes - so it shouldn't be surprising Pros/cons - RIFE/DAIN has those other major downsides mentioned earlier too (slow, 2x multiples, limited "tweakable" settings, scenechanges not as clean, harder to use in a sense - although there are dedicated GUI's for RIFE/DAIN - so for general public they are actually easier to use than avisynth or vapoursynth) Quote:
DAIN - because it's sooo slow I would avoid if possible. But there are some situations and frames where it does slightly better (or worse) than RIFE. |
|||
|
|
|
|
5th May 2021, 02:59
|
#24 | Link |
|
Registered User
Join Date: Sep 2007
Posts: 5,377
|
Here is the apng treatment with part of the fence clip, jm_fps vs. RIFE. (Same deal, open in a browser tab)
https://www.mediafire.com/file/2cwoe..._apng.zip/file Clearly the RIFE foreground object boundaries are cleaner with significantly reduced "ring" of artifacts. Both have problems on other parts of the fence (not shown in the apng) - but RIFE a better starting point in this situation because there is less cleanup to do in other programs. |
|
|
|
|
7th May 2021, 01:27
|
#25 | Link |
|
Registered User
Join Date: Mar 2018
Posts: 447
|
I have some results to report. But first, let's go briefly over the setup. I decided to use the AviSynth version of MVTools2 as I think it might be the definitive version, created by master pinterf himself and thorougly tested by myself. So I will not include the script I used with Zopti here, but I can link to it if anyone is interested. The script uses MFlowFPS & Co to create intermediate frames that in the end can be compared to the original frames of the source. The basic idea is: (I may not have the charting skills of Mark but I can try... )
Code:
0 1 2 3 time (frames)
----------------------------------
[A ] [B ] [C ] [D ] original frames
[A ] [AB] [B ] [BC] [C ] [CD] [D ] 1) interpolate new frames (MFlowFPS)
[AB] [BC] [CD] 2) remove original frames (SelectOdd)
[AB] [BB] [BC] [CC] [CD] 3) interpolate new frames again (MFlowFPS)
[BB] [CC] 4) leave only latest interpolated frames (SelectOdd)
[B ] [C ] 5) compare original and interpolated frames (GMSD)
[BB] [CC]
I wanted to get something running quickly so I used an old template I had which doesn't have all the parameters of MAnalyse. Notably levels, pzero, pglobal, dct and scaleCSAD are missing. I will add those in the coming runs. I used the GMSD metric as I know from experience that it's more sensitive than SSIM. MDSI might be good also but GMSD is a bit more convenient to use as it doesn't need RGB clips. I started with five relatively short runs (10 000 iterations each) to see how consistent the results are. If they are it's a good sign that the search is long enough. That's not the case here though. Code:
10 000 iterations run 1 run 2 run 3 run 4 run 5 GMSD 3.0752501 2.995727 2.922894 2.9211512 2.9990165 MSuper pel 4 4 4 4 4 sharp 2 1 1 1 2 rfilter 2 2 4 4 1 MAnalyse blksize 24 8 16 16 16 search 3 3 5 3 5 searchparam 6 1 4 5 3 pelsearch 9 9 9 8 13 lambda 11 (99) 20 (20) 10 (40) 6 (24) 22 (88) lsad 7847 10006 5789 6936 10576 pnew 251 180 247 240 254 plevel 2 0 0 2 0 overlap 12 2 0 0 6 overlapv 0 4 4 0 4 divide 2 0 2 2 0 global true true true true true badSAD 8779 1938 1445 8315 6540 badrange 22 7 10 33 11 meander true true true true true temporal true true false true true trymany false false false false false MFlowFPS ml 209 87 50 84 19 mask 2 2 2 2 2 The next phase was running three longer optimizations, 100k iterations each. Code:
100 000 iterations run 1 run 2 run 3 GMSD 2.843625 2.8578067 2.9011016 MSuper pel 4 4 4 sharp 2 1 1 rfilter 1 2 4 MAnalyse blksize 16 16 16 search 4 4 5 searchparam 2 2 4 pelsearch 14 10 6 lambda 3 (12) 2 (8) 284 (1136) lsad 10249 15931 10 pnew 97 101 230 plevel 0 1 1 overlap 0 0 0 overlapv 0 0 0 divide 2 2 2 global true true true badSAD 79 842 5749 badrange 5 7 18 meander true true true temporal true true false trymany false false false MFlowFPS ml 56 48 21 mask 2 2 2 This is what the best result (so far) looks like (note that this is only showing the interpolated frames)  As you can see it cannot compete with RIFE but at least it's better than the plain jm_fps result (I assume that's what was used) poisondeathray showed. Also it's clear to me that it's not even possible to get a nice foreground/background separation by swizzling 16x16 blocks around. This clearly needs MRecalculate to use smaller blocks. I was curious about the chosen blksize 16 and why wouldn't for example 8x8 give better results. Perhaps the smaller blocksize cannot track the background coherently even though the object boundaries would look better. So I started some short runs (10 000 iterations again) to see what 8x8 blocks look like. Code:
10 000 iterations run 1 run 2 run 3 run 4 run 5 GMSD 2.9374497 2.9236088 2.9058511 2.8954031 2.9246368 MSuper pel 4 4 4 4 4 sharp 2 2 2 2 2 rfilter 3 3 2 2 1 MAnalyse blksize 8 (LOCKED) search 3 4 2 4 5 searchparam 1 1 1 1 1 pelsearch 2 27 4 9 12 lambda 0 17 8 6 15 lsad 2313 7154 15093 10296 1975 pnew 248 242 250 244 186 plevel 1 0 1 0 0 overlap 2 2 2 2 0 overlapv 2 2 2 2 0 divide 0 0 0 0 2 global false false false false true badSAD 3171 3176 3149 3049 1967 badrange 12 21 13 15 10 meander true true true true true temporal true false true true true trymany false false false false false MFlowFPS ml 253 106 183 84 115 mask 2 2 2 2 2 Curiously the results on average are better than the first 5 runs. It could be for two reasons: the search space is now smaller which helps Zopti find the good combinations faster OR the 8x8 blocks really are better but they are very hard to find. I will do 100k iterations next to find out. It occurred to me that it's not that difficult to improve the 16x16 block output. The idea is to run the same interpolation multiple times with different x,y offsets within the 16x16 block and combine the results by taking the median value of each pixel. For example this is what it looks like with 9 samples (offsets 0, 6, 12 in each axis):  This is obviously 9 times slower but is another nice trick we can use. My original idea was to use the SAD values of MMask to select only the blocks with best vectors but that turned out to be too blocky. |
|
|
|
|
25th May 2021, 01:27
|
#26 | Link |
|
Registered User
Join Date: Mar 2018
Posts: 447
|
Time for a little status update. I continued with the longer (100000 iterations) 8x8 block tests. The results were:
Code:
100 000 iterations run 1 run 2 run 3 GMSD 2.8606837 2.8584862 2.8553133 MSuper pel 4 4 4 sharp 2 1 1 rfilter 1 1 1 MAnalyse blksize 8 (LOCKED) search 4 1 1 searchparam 1 1 1 pelsearch 7 2 2 lambda 7 6 3 lsad 18930 932 2084 pnew 241 249 249 plevel 1 0 1 overlap 2 2 2 overlapv 2 2 2 divide 0 0 0 global false false false badSAD 3234 3167 3170 badrange 13 12 12 meander true true true temporal true true true trymany false false false MFlowFPS ml 40 41 41 mask 2 2 2 I was a bit puzzled as to why the optimal searchparam value (which controls the search radius) is very low, just 1 in the 8x8 case and 2 for the 16x16 case. I would have expected that larger radius cannot hurt the results but it looks like it can, and a lot! I did some exhaustive searches around the optimal values just changing searchparam and pelsearch and drew some heat maps for each search algorithm. Results below (note that searchparam is named searchRange and pelsearch is named searchRangeFinest, it controls the search radius at the finest level): 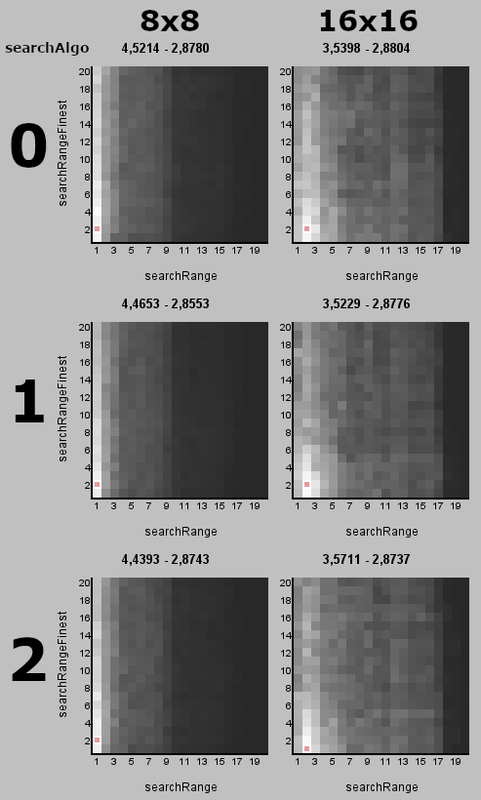 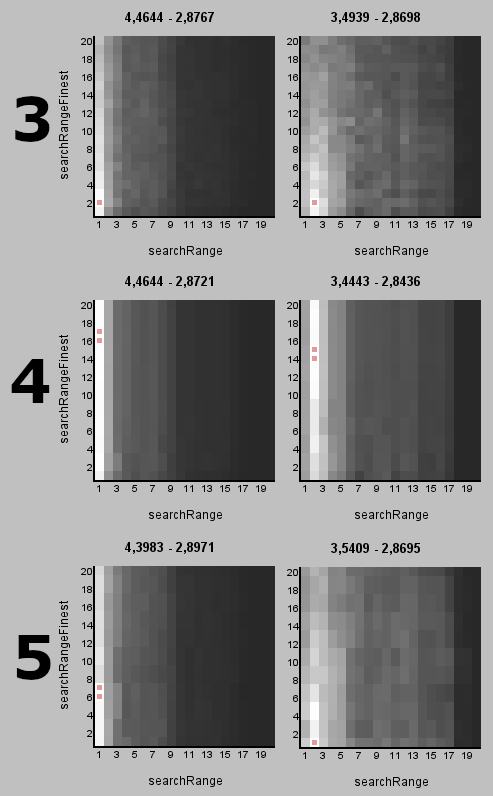 The brighter the color, the better the GMSD score. The best value is highlighted by a red dot (or dots if there are multiple best results). The decimal numbers above the maps are the worst and the best found GMSD score. This confirms that there is no better alternative to these low search radiuses. This is my guess as to why larger radius doesn't work very well here: The background has a very repetitive pattern and that means there can be very good SAD scores at far away locations. So with a large search range some blocks will get best score at those far away locations and some will find the closest "correct" location and the mixing up of these far/close vectors looks ugly. The following gif demonstates what it looks like with search ranges 2 (optimal), 4 and 8:  Another mystery is that the search algorithm 3 (exhaustive search) was not the best one in either 8x8 or 16x16 case. The docs state that "It is slow, but it gives the best results, SAD-wise". Perhaps there are other factors involved and the best SAD is not all that matters. Algorithm 4 (hexagon search) is a curious case, the pelsearch parameter has very little effect on the result and the best result is at pelsearch 14-17 while with other algorithms it is at around 2 (algorithm 5 is an exception as well). I guess this explains why it was found quite often as the best algorithm. It's also easy to see that with 16x16 blocks it's overall easier to find good results, there is a steep drop to bad results with searchRange > 9 with 8x8 blocks while that dropoff happens at searchRange > 17 with 16x16 blocks. Also the bad results with 8x8 blocks are much worse (around 4,4) than with 16x16 blocks (around 3,5). I have more results to share but that's enough for now. 
Last edited by zorr; 25th May 2021 at 01:58. |
|
|
|
|
26th May 2021, 00:28
|
#27 | Link |
|
Registered User
Join Date: Mar 2018
Posts: 447
|
Some further analysis about the search range: looking at the vectors shows what is actually going on:
 These are the backward vectors of a single frame with search range 2 (good) and search range 8 (bad). On the left are the vectors drawn with MShow and details on one single block. On the right is the horizontal vector direction displayed as brightness using MMask. What happens with search range 8 is that some vectors switch to opposite direction (the vx changes from -83 to 64). The same however doesn't happen on the forward vectors. MFlowFPS then has to deal with two conflicting vector directions and the end result is that some pixels are not moving anywhere (or very little) while those around them are. Usually this kind of problem is avoided by making the vectors more coherent using truemotion=true or setting lambda, lsad, pnew, plevel and global individually. Perhaps Zopti used a shortcut here and avoided the problem by using a very focused search range. It would be interesting to force a larger search range and let Zopti figure out good values for the aforementioned parameters. Or perhaps it's simply not possible to achieve as good of a GMSD score using a larger search range because more coherent vectors make object boundaries harder to follow. EDIT: The default search range of MVTools2 is 2 so what is used here is actually very normal. A larger search range would only be useful with faster motion. Last edited by zorr; 26th May 2021 at 00:39. |
|
|
|
|
19th June 2021, 01:06
|
#28 | Link |
|
Registered User
Join Date: Mar 2018
Posts: 447
|
The tests so far have been somewhat informative but they're not really telling about the full capabilities of MVTools because we didn't use all the possible parameters. The most important ones missing are levels, pzero, pglobal, dct and scaleCSAD. MSuper has parameters vpad and hpad but they only affect the edge blocks so we'll use the default values for those. But as we're adding five new variables and making the search even harder it's also a good idea to see what we've learned so far and try to eliminate parameters from the search that have known good values.
I identified a couple of parameters that always have the same value when we look at the best results: pel (of MSuper), meander (of MAnalyse) and ml (of MFlowFPS). Pel is 4, meander is true and ml is 2. I usually also look at how much better the best value is compared to other values and the heatmap gives a good overview. 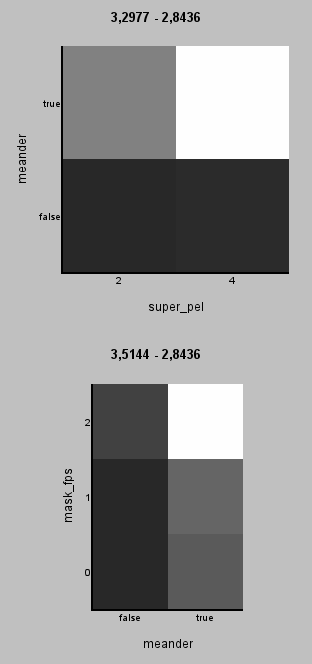 The best combinations are the white blocks and the worst are the dark ones. The color of each block reflects the best found result in each. Meander=false results in much worse results, somewehere around 3.29. Meander is "Alternate blocks scan in rows from left to right and from right to left." and defaults to true. I'm not quite sure why this has such a large effect on the quality, but since it has we can simply "lock" this parameter to true. Pel is another parameter where value 4 gives clearly better results than 2 (and I didn't even test 1) at least on this particular test case. Pel controls the precision of the motion vectors so it's quite understandable that a larger precision helps. It's not necessarily always the case though but it's safe to lock the value to 4 for these tests. Ml (mask_fps in the heatmap) with value 2 seems to give much better results than 0 or 1. Ml affects the strength of occlusion mask, the lower the value the stronger the occlusion. Looks like occlusion mask is not helping in our tests so we lock the value as 2. While there weren't other parameters with a single clearly best value there are others where we can limit the range of tested values. In the initial runs I tested blockSizes 8,16,24,32,48,64 and all the search algorithms. Let's see a heatmap of those: 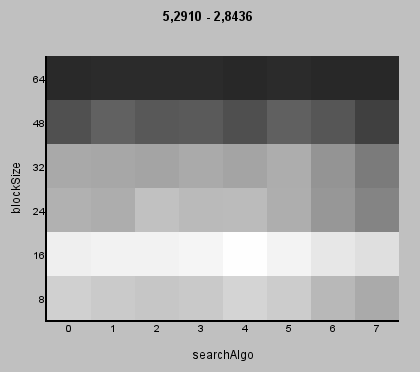 Looks like blockSize 16 is much better than any other. I still wouldn't lock it down but we can at least remove the block sizes 32 and above, leaving just 8,16 and 24. I'm also adding new block sizes 3,4 and 6 (those didn't exists when I originally made the zopti script). This also means the maximum values for overlap and overlapv are now 12 (half of 24). Search algorithms 6 and 7 are not quite as good as the others. Algorithm 6 is "pure horizontal exhaustive search" and 7 is "pure vertical exhaustive search" which explains why. We can leave them out from the next tests. Next we'll look at the search ranges (searchparam and pelsearch). The heatmap shows only the top 50% of results so we can see them better. 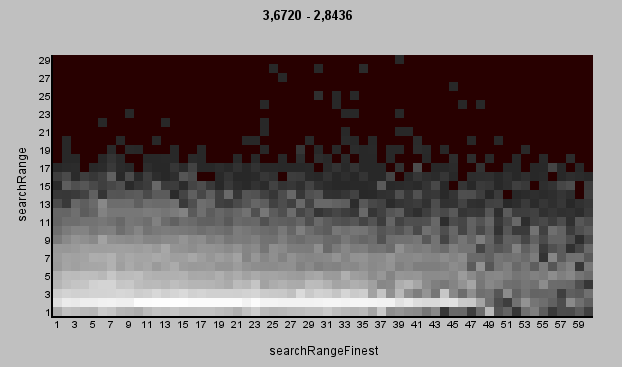 The original search range was 1..30 for the search range and 1..60 for the finest level. The optimal values were 2-4 and 6-14 respectively. The best value of 2 for searchparam is clearly visible, for pelsearch many values give almost as good result as the best value of 14. Let's limit the search range to 1..8 and the finest level to 1..30. I did an exhaustive scan of parameter LSAD to see how changing just that one parameter will change the result. The other parameters were using the best values found for 8x8 block size. 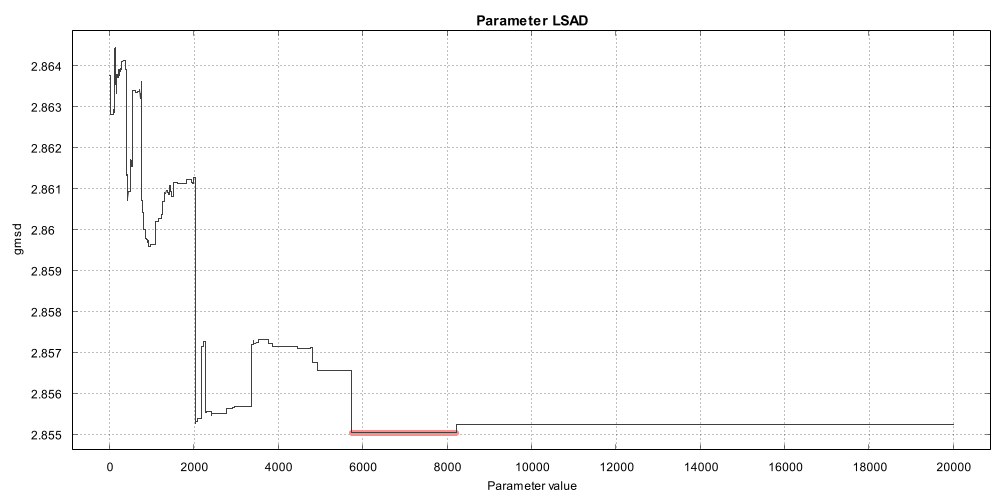 The red portion of the line is the best result and looks like many values give the exact same result. There are other sections where changing LSAD doesn't change the result at all. Looks like it doesn't pay to try every possible LSAD value, we can add a filter to only test values divisible by 100. Also the results are not changing at all after a bit over 8000 so the search range can be limited to max 10000. It's also worth mentioning that the effect of LSAD is very small, even the worst possible LSAD drops the result to 2.864 from 2.855. What about badSAD? 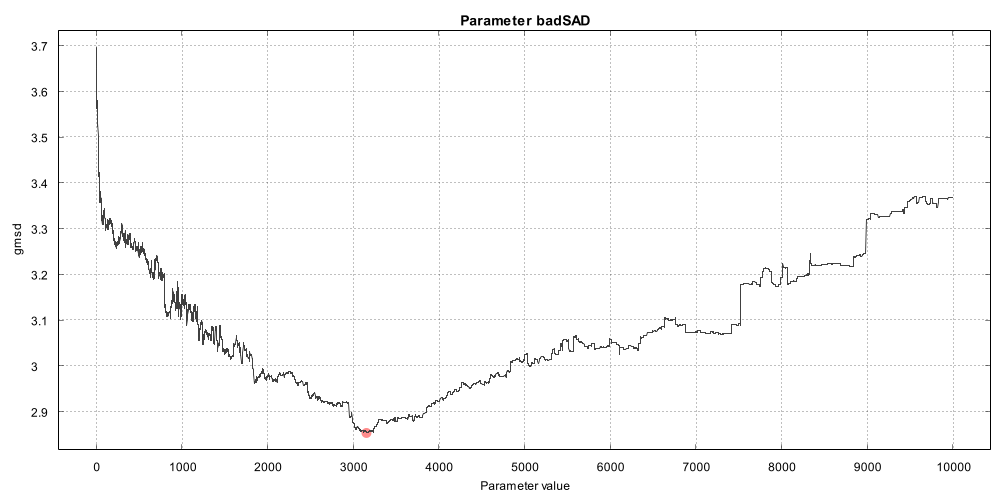 The effect of badSAD is much stronger, choose it badly and the result drops to 3.7. BadSAD doesn't have flat areas but at least we can set the maximum to 8000. Lastly we look at lambda. I used lambda range 0..20000 in the first tests but the best lambdas were very small, just 12 in the best found result. We'll limit lambda range to 0..200. Below the best result per lambda value (the blue line shows the number of tests per lambda value). Note that this chart was not from an exhaustive search but just shows the best found result from the original search runs, that's why the line jumps so wildly. 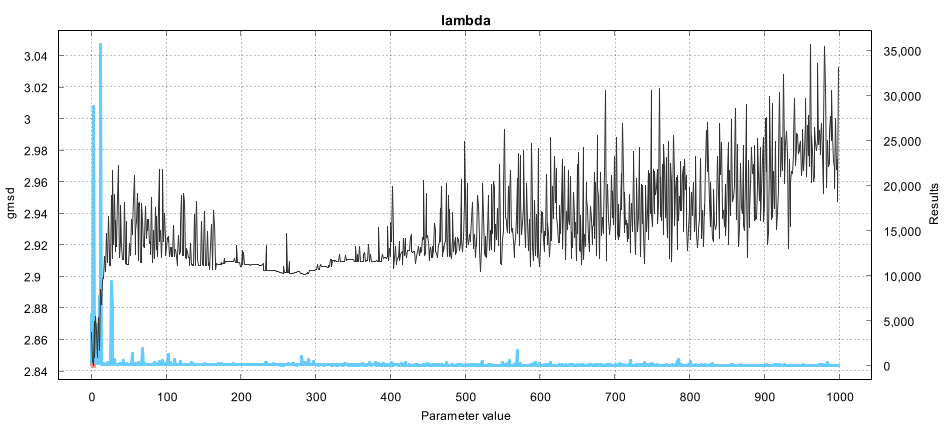 One more change is that we allow negative values for parameter badRange which is the range of wide search for bad blocks. The negative sign indicates that the algorithm is switched to exhaustive search. To be continued... Last edited by zorr; 19th June 2021 at 01:20. |
|
|
|
|
19th June 2021, 11:45
|
#29 | Link |
|
Pig on the wing

Join Date: Mar 2002
Location: Finland
Posts: 5,733
|
Very interesting results indeed. Most of the MVTools parameters are quite fuzzy so it's nice to see something like this.
As you seem to enjoy testing, incorporating MRecalculate could be a logical next step after the normal MAnalyse path. I've noticed (just by looking at MShow results) that it stabilises the vector field quite a lot.
__________________
And if the band you're in starts playing different tunes I'll see you on the dark side of the Moon... |
|
|
|
|
19th June 2021, 23:50
|
#30 | Link | |
|
Registered User
Join Date: Mar 2018
Posts: 447
|
Quote:
|
|
|
|
|
|
22nd June 2021, 00:37
|
#31 | Link |
|
Registered User
Join Date: Mar 2018
Posts: 447
|
Let's see the results, finally.
As usual I did some 10000 iteration runs first to get a little taste of things to come. The best result was 2.7709792 with blockSize 8. Very promising, that's already better than what we could achieve before! Next up was three runs of 100 000 iterations. Code:
2.707417 blockSize 8 2.8104672 blockSize 16 2.7966063 blockSize 16 Code:
2.730084 Code:
2.701151 in 117240 iterations Code:
2.718272 in 165720 iterations Code:
run 1 run 2 run 3 GMSD 2.707417 2.701151 2.718272 iterations 100 000 117 240 (dynamic) 165 720 (dynamic) MSuper pel 4 (LOCKED) 4 (LOCKED) 4 (LOCKED) sharp 1 1 1 rfilter 2 2 0 MAnalyse blksize 8 8 (LOCKED) 8 (LOCKED) * levels 0 -1 -2 search 5 5 5 searchparam 1 1 1 pelsearch 3 6 4 lambda 3 6 5 lsad 4900 8200 4100 pnew 159 161 168 * pzero 6 34 33 * pglobal 3 11 137 plevel 0 2 1 overlap 0 0 2 overlapv 4 4 2 * dct 1 1 1 divide 0 0 0 global true true true badSAD 1346 943 1712 badrange -8 2 -9 meander true (LOCKED) true (LOCKED) true (LOCKED) temporal false false false trymany false false false * scaleCSAD 2 2 2 MFlowFPS ml 36 18 29 mask 2 (LOCKED) 2 (LOCKED) 2 (LOCKED) The parameters marked with * are the new MAnalyse params which we didn't use earlier. Since 8x8 blockSize was better than 16x16 but was kinda hard to find until we locked it down, perhaps we should also try locking the blockSize to 6x6: Code:
2.7766657 in 214080 iterations Let's get back to those top 3 results. There are again parameters with the same value in all three and we can probably try some tighter search ranges as well. Code:
LOCKED: sharp = 1 searchAlgo = 5 searchRange = 1 dct = 1 divide = 0 globalMotion = true temporal = false trymany = false scaleCSAD = 2 Range limited: searchRangeFinest 1..20 lambda 0..12 pnew 130..200 pzero 0..100 badSAD 100..3000 badRange -20..20 maskScale 1..100 Code:
2.6988451 in 101880 iterations Code:
run 1 GMSD 2.6988451 iterations 101 880 (dynamic) MSuper pel 4 (LOCKED) sharp 1 (LOCKED) rfilter 2 MAnalyse blksize 8 (LOCKED) * levels -2 search 5 (LOCKED) searchparam 1 (LOCKED) pelsearch 2 lambda 1 lsad 400 pnew 158 * pzero 3 * pglobal 3 plevel 2 overlap 0 overlapv 4 * dct 1 (LOCKED) divide 0 (LOCKED) global true (LOCKED) badSAD 1344 badrange -7 meander true (LOCKED) temporal false (LOCKED) trymany false (LOCKED) * scaleCSAD 2 (LOCKED) MFlowFPS ml 30 mask 2 (LOCKED) Code:
2.7016597 All right, this concludes the tests on MAnalyse + MFlowFPS. Some random notes about the parameters we found:
ScaleCSAD and trymany can be seen below as a heatmap. The larger the weight of chroma the better the result. And trymany=true consistently results in worse score. 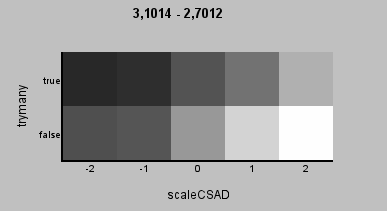 So how much better is 2.6988451 than 2.843625? What do these values even mean? The script calculates the total GMSD score. There are 27 measured frames so the average per frame is almost precisely 0.01. It's also important to remember that we're measuring the quality after two interpolations while the frame-doubling only needs one so the quality in practical use is perhaps twice better, about 0.005 per frame. I wanted to see how the optimized script compares to RIFE so I did a similar double-interpolation using RIFE ncnn Vulkan with the latest v3.1 model and measured the GMSD. RIFE's total was 2.192934 (NOTE: RIFE works with images and round-trip YV24->png->YV24 gives GMSD penalty of 0.336003). The chart below shows the per frame GMSD scores for the initial version, the latest version with all the parameters and RIFE. 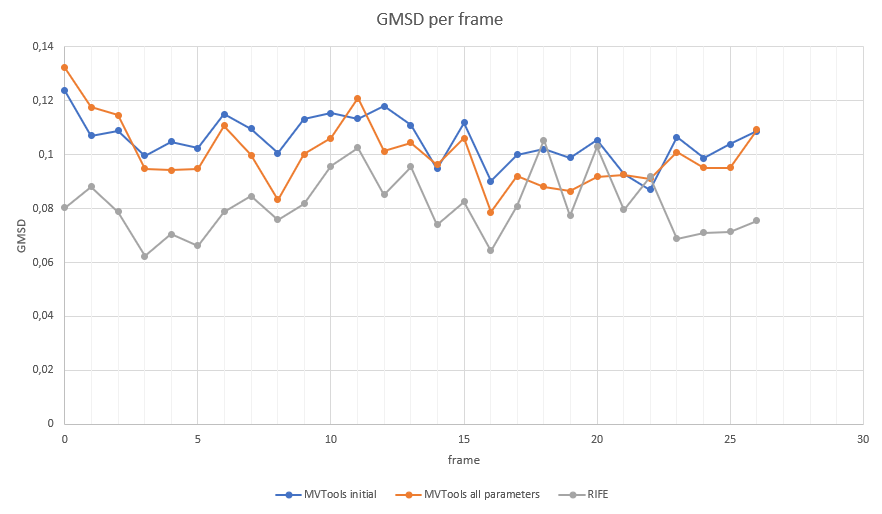 On some frames MVTools actually pulls ahead but RIFE is still better overall. Also notable that the latest MVTools script is actually worse than before on some frames and two worst single frame GMSD scores are from this latest version. We could of course optimize for minimizing the largest per frame GMSD and get different results. Let's compare some frames where the latest script did better (frame 8) and one where it did worse (frame 11). These are the doubly-interpolated frames.  And here's a comparison of the latest MVTools script and RIFE. Frame 3 shows where RIFE is much better and frame 18 shows where MVTools beats RIFE.  Here's the complete MVTools result with score 2.6988451, again only showing the interpolated frames.  The next episode is about MBlockFPS, can it beat the best result of MFlowFPS? |
|
|
|
|
8th September 2021, 18:33
|
#32 | Link |
|
Registered User

Join Date: Jul 2016
Location: Mansfield, Ohio (formerly San Jose, California)
Posts: 280
|
@zorr, this is all quite amazing, and so are you -- I'm becoming a fan.
 I'm digesting it. My mind is somewhat boggled by the tech jargon. I've found that, rather than going from 24000/1001fps to 60000/1001fps (i.e. 2.5x), I get better results by forcing 24000/1001fps to 24fps -- 0.1% metadata speed up (not a transcode) to cinema running time -- then going from 24fps to 120fps (i.e. 5x) and then letting the TV drop alternate frames to 60fps. I'm still using SVPflow because it's all I know, but it does seem to do a better job if the interpolation is integer (e.g. 5x). |
|
|
|
|
8th September 2021, 21:03
|
#33 | Link | |
|
Registered User

Join Date: Oct 2001
Location: Germany
Posts: 7,277
|
Quote:
|
|
|
|
|
|
8th September 2021, 23:07
|
#34 | Link | |||
|
Registered User
Join Date: Mar 2018
Posts: 447
|
Quote:
Quote:
Quote:

|
|||
|
|
|
|
9th September 2021, 17:37
|
#35 | Link | |
|
Registered User
Join Date: Jul 2016
Location: Mansfield, Ohio (formerly San Jose, California)
Posts: 280
|
Quote:
FFprobe appears to be unreliable. Do you know of another way to probe video streams? Also, Selur, is there a reason for "DAR 5:4" instead of "DAR 4:3"? Input #0, matroska,webm, from 'Fensterladen.mkv': Stream #0:0: Video: h264 (High 4:4:4 Predictive), yuv420p(progressive), 720x576, 25 fps, 25 tbr, 1k tbn (default) NOTE: DAR,SAR missing Input #0, matroska,webm, from 'Ferdinand06.mkv': Stream #0:0: Video: h264 (High), yuv420p(tv, bt709, progressive), 1280x720 [SAR 1:1 DAR 16:9], 25 fps, 25 tbr, 1k tbn (default) Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'forInterpolation.mp4': Stream #0:0(eng): Video: h264 (High) (avc1 / 0x31637661), yuv420p, 3840x2160 [SAR 1:1 DAR 16:9], 62614 kb/s, 29.97 fps, 29.97 tbr, 30k tbn (default) Input #0, matroska,webm, from 'Hamsterzaun.mkv': Stream #0:0: Video: h264 (High), yuv420p(top first), 1920x1080 [SAR 1:1 DAR 16:9], 25 fps, 25 tbr, 1k tbn (default) NOTE: 'interlaced_frame=1','top_field_first=1','repeat_pict=0' but is not interlaced. Input #0, matroska,webm, from 'Hochhaus.mkv': Stream #0:0: Video: h264 (High), yuv420p(tv, bt709, top first), 1920x1080 [SAR 1:1 DAR 16:9], 25 fps, 25 tbr, 1k tbn (default) NOTE: 'interlaced_frame=1','top_field_first=1','repeat_pict=0' but is not interlaced. Input #0, matroska,webm, from 'Jalousie.mkv': Stream #0:0: Video: h264 (High 4:4:4 Predictive), yuv420p(progressive), 720x576, SAR 1:1 DAR 5:4, 25 fps, 25 tbr, 1k tbn (default) Input #0, matroska,webm, from 'Krone 25 fps.mkv': Stream #0:0: Video: h264 (High), yuv420p(tv, bt470bg, progressive), 720x576 [SAR 12:11 DAR 15:11], SAR 1:1 DAR 5:4, 25 fps, 25 tbr, 1k tbn (default) NOTE: differing DAR,SAR Input #0, matroska,webm, from 'MusteramArm.mkv': Stream #0:0: Video: h264 (High 10), yuv420p10le(progressive), 720x576 [SAR 1:1 DAR 5:4], 25 fps, 25 tbr, 1k tbn (default) Input #0, matroska,webm, from 'Torzaun.mkv': Stream #0:0: Video: h264 (High 4:4:4 Predictive), yuv420p(progressive), 720x576, 25 fps, 25 tbr, 1k tbn (default) NOTE: DAR,SAR missing Input #0, matroska,webm, from 'Vogelkaefig.mkv': Stream #0:0: Video: h264 (High 4:4:4 Predictive), yuv420p(progressive), 720x576, SAR 1:1 DAR 5:4, 25 fps, 25 tbr, 1k tbn (default) |
|
|
|
|
|
9th September 2021, 18:17
|
#36 | Link | ||
|
Registered User
Join Date: Oct 2001
Location: Germany
Posts: 7,277
|
Quote:
Quote:
|
||
|
|
|
 |
|
|



 Linear Mode
Linear Mode

