Welcome to Doom9's Forum, THE in-place to be for everyone interested in DVD conversion. Before you start posting please read the forum rules. By posting to this forum you agree to abide by the rules. |
 14th July 2021, 21:03
14th July 2021, 21:03
|
#1161 | Link | ||
|
MKVToolNix author

Join Date: Sep 2002
Location: Braunschweig, Germany
Posts: 4,281
|
I've reconsidered and "improved" (= fixed) the parser's validation of prefixes. Pretty much all examples you listed now test correctly, as do a lot of their variants for which I added a lot more test cases (e.g. "de-1901" and "de-1996" being valid, "de-1901-1996"). A side effect is that the order matters now, meaning "sl-rozaj-biske" is considered valid whereas "sl-biske-rozaj" isn't.
One thing I haven't changed (and don't think I ever will) is supporting legacy codes. Quote:
Quote:
I'll look into downloading the lists directly from ISO's website directly (e.g. ISO 639-3 is available here) and parsing those. Thanks for all the testing & the feedback!
__________________
Latest MKVToolNix is v83.0 If I ever ask you to upload something, please use my file server. |
||

|

|
|
15th July 2021, 02:55
|
#1162 | Link | |||
|
李姗倩 Lǐ Shān Qiàn

Join Date: Nov 2002
Posts: 1,340
|
Quote:
Code:
<!DOCTYPE html><html lang="sl-rozaj-biske"> <head><title>test</title></head></html> Code:
<!DOCTYPE html><html lang="sl-biske-rozaj"> <head><title>test</title></head></html> Quote:
Let's say the audio track is Cantonese. Language=yue is impossible in the current Matroska specs, so we have Language=chi. The question is, can we have LanguageIETF=yue at the same time? Or should it be LanguageIETF=zh-yue even though being redundant and not the best practice? This may become an issue when players actually start reading LanguageIETF. Perhaps we're going to have to ask player-side devs to support both yue and zh-yue equally, just like standard and legacy font mime types. Quote:
 RFC 4646 Appendix B says zh-min-nan (grandfathered but valid), not zh-mnp-nan (and neither zh-mnp nor zh-nan is valid). As LanguageIETF in Matroska, if we use zh-yue instead of yue, then we'll have to use zh-min-nan instead of nan, for the same reason. This point itself may be debatable, though. RFC 4646 Appendix B says zh-min-nan (grandfathered but valid), not zh-mnp-nan (and neither zh-mnp nor zh-nan is valid). As LanguageIETF in Matroska, if we use zh-yue instead of yue, then we'll have to use zh-min-nan instead of nan, for the same reason. This point itself may be debatable, though.EDIT: The last paragraph is wrong. Both zh-mnp and zh-nan are valid, and also zh-min-nan is technically valid too: "nan" (preferred) = "zh-nan" (synonym) = "zh-min-nan" (grandfathered), while "ms-min" = "min" ≠ "zh-min". Really confusing... Last edited by Liisachan; 15th July 2021 at 05:45. |
|||
|
|
|
|
15th July 2021, 08:27
|
#1163 | Link | ||||
|
MKVToolNix author
Join Date: Sep 2002
Location: Braunschweig, Germany
Posts: 4,281
|
Quote:
Quote:
If you need to support legacy players in such situations, you can use mkvpropedit after multiplexing. It will treat the property "language" similarly to mkvmerge, namely setting both LanguageIETF and (Legacy)Language, but it also knows the "language-ietf" property which will only set LanguageIETF. So:
Using "--language 1:zh-yue" works, too. In that case mkvmerge will set LanguageIETF=zh-yue and (Legacy)Language=chi as chi is the 639-2 code associated with the 639-3 code zh. So as to the question what best to do in order to be properly compatible, let's just say it's complicated. My take: decide on either of the following:
[1] This can even be automated. The GUI supports running arbitrary programs after multiplexing. One could write a script (in whatever language) that uses mkvmerge to query the current track languages. For all tracks with a language of "yue" it runs mkvpropedit on the file & uses the aforementioned "--set language=chi --set language-ietf=yue" for those tracks. Then configure the GUI to run that script after mutliplexing & use "yue" as the track language going forward. Quote:
One thing be both definitely agree on: Quote:
__________________
Latest MKVToolNix is v83.0 If I ever ask you to upload something, please use my file server. |
||||
|
|
|
|
15th July 2021, 16:59
|
#1164 | Link | |
|
李姗倩 Lǐ Shān Qiàn
Join Date: Nov 2002
Posts: 1,340
|
The recent updates are impressive, but there seem to be some accidental regressions. A few basic tags are now refused: Latin (la; lat), Sign Languages (sgn), Artificial languages (art). Also, some minority tags, previously recognized, are now refused (lsg, rsi...).
I suggest you use https://www.iana.org/assignments/lan...ubtag-registry which is solid and more up-to-date than SIL's tables also including recently added 3-letter codes (bic, bij, blg...) & script codes (Ougr, Pcun...). Quote:
Code:
Type: extlang Subtag: min Prefix: ms Code:
Type: grandfathered Tag: zh-min The current test version of MKVToolnix tends to refuse deprecated tags. Totally refusing deprecated tags, though, one can't use zh-yue: Code:
Type: redundant Tag: zh-yue Description: Cantonese Added: 1999-12-18 Deprecated: 2009-07-29 Preferred-Value: yue I kind of understand why zh-yue (Deprecated, Redundant) is recommended over yue (standardized in 2009) in Matroska. But then, because of similar, practical reasons, shouldn't application/x-truetype-font be recommended over font/ttf? What's the point in using font/ttf, when both old and new players understand the legacy mime but not all players don't recognize font/ttf (standardized in 2017) yet? If anything, I'd make the "Use standard mime types for font attachments" checkbox as opt-in for those who really want to use them: enabling it doesn't really improve anything, except maybe the file size will become smaller by a few bytes, while confusing or upsetting a few end users (like those who are still using the last official version of MPC-HC). Imho the mime-type transition was slightly premature, with few advantages; it could have waited for a little longer, until most MPC-HC users switch to clsid2 builds or -BE. SourceForge, once a great site, is making things difficult, still recommending old MPC-HC (which doesnt recognize font/ttf), along with the latest stable version of MPC-BE. |
|
|
|
|
|
15th July 2021, 17:39
|
#1165 | Link | ||||||
|
MKVToolNix author
Join Date: Sep 2002
Location: Braunschweig, Germany
Posts: 4,281
|
Quote:
Artificial got lost 'cause I only process 639-3 at the moment and "art" is only part of 639-2 but not of 639-3. In fact, 639-3 doesn't contain language collections while 639-2 do, and I totally forgot about that fact. I'll re-add processing 639-2 lists & disable filtering by type. That'll add another 1.000 entries or so Quote:
I am using the registry for extended language sub-tags & variants, though. Quote:
Quote:
Quote:
Quote:
With your arguments you could even refuse to ever add any type of new element (such as LanguageIETF) to Matroska ever again as there are always players out there refusing to play files that contain elements they don't know about, and we don't know when users have switched over from those players. It's a losing game. For those who have problems with the MIME types, several options exist. It's up to the user to decide how much legacy support they want to offer.
__________________
Latest MKVToolNix is v83.0 If I ever ask you to upload something, please use my file server. |
||||||
|
|
|
|
15th July 2021, 21:04
|
#1166 | Link | |||
|
李姗倩 Lǐ Shān Qiàn
Join Date: Nov 2002
Posts: 1,340
|
A weird behavior, perhaps introduced somewhere between v52 and v56. When the language name for a 3-letter code (e.g. 'hmj') is exactly 2-letter (e.g. 'Ge'), and this 2-letter name is not identical to any valid language tag, then the 2-letter string is accepted as if it were a valid language tag.
Exmaple (note "ge" is not a valid language tag) Code:
mkvmerge -o out.mka --language 0:ge in.ogg mkvinfo out.mka ... | + Language: und | + Language (IETF BCP 47): hmj Quote:
Quote:
I have nothing against font/ itself either, but the switch was a bit abrupt. I thought you agreed that the mime type transition wouldn't be a surprise attack, and that there would be some kind of advance warning. If I had known there were going to be MIME type changes, I could have tested pre-release versions and chances are, the MIME-related bugs in v58/59 wouldn't have existed. But v58 had been already released, so it's pointless to say this. The problems were fixed rather quickly, for which I'm thankful Quote:
Anyway, it was unfortunate that there didn't exist registered mime types for font files... it's no one's fault. Because of this experience, it seems natural to ask this pre-emptively: maybe should we use "yue" instead of "zh-yue" from the beginning, so that the value of languageIETF will remain stable? Just wondering, not insisting anything. Perhaps whichever is fine, because hopefully a good player in the future will support both. |
|||
|
|
|
|
15th July 2021, 21:58
|
#1167 | Link | ||||
|
MKVToolNix author
Join Date: Sep 2002
Location: Braunschweig, Germany
Posts: 4,281
|
Quote:
You can also use the language called "Gen" as an example; it works, and its code "gej" is written to the Matroska file. I'll definitely fix this, most likely by removing the comparison to the name field as I don't think I ever intended that to work. Quote:
What drove me to update magic for the Windows build wasn't to make behavior the same across OSses, either. Instead, I primarily wanted to update in order to remove a ton of potential security issues in said library. magic deals with untrusted material from untrusted sources. I have a moral responsibility to keep it as up to date as possible. Now why did I wait so long to update? That wasn't intentional either. I'm using the "MXE" project for cross-compiling from Linux to Windows. MXE functions a bit like a Linux distribution, just for providing huge set of build recipes that can compile everything from the compiler & the libraries & the programs on Linux to be run on Windows so that you can build your own program on top of that infrastructure. I'm relying on the MXE project keeping their build recipes up to date. For magic, unfortunately, that build recipe was quite stale, it turned out. After updating the library I realized that it featured a change to font MIME types. When I compared that to Linux I noticed that on Linux the new font types had already been in use for quite a bit. So that seemed to be as good a time as any to change over officially as part of my releases had done so for a while. If I had planned it all in advance, this would likely have gone down differently. It was more of an accident, though, and things were already broken. Quote:
Quote:
I wrote earlier about the three options I see for users. I will not and cannot make a recommendation. I know what I'd do for my personal files, were I to speak Chinese, which I'm not, but personal libraries are just one of the many use cases, a lot of them with widely different requirements. So yeah. 🤷 With BCP 47 I think players will have to do a lot of leg work for "proper" support for them, whatever "proper" means, exactly. In MKVToolNix I only need to consider creating (= letting the user input them), validating (either from user input or from existing data) and partially with displaying them. For players, the "displaying them" part becomes that much more important, and there are so many things to consider, given that tags can become so large, and replacing the subtags with their corresponding names might yield huge huge-readable strings. On top of that players have to implement matching: letting the user chose their preferences, then matching those preferences to existing tags and deciding which to auto-select. I don't envy them that work, and I fear most players won't put too much work into it (if any at all; sticking to (Legacy)Language is probably appealing to a lot of developers). BCP 47 is bloody huge. But just like Unicode, this isn't actually a technical problem, it's a human problem, as we were the ones to create all those languages and scripts and symbols. Basically we all have ourselves to blame for all the work we now must do 😁
__________________
Latest MKVToolNix is v83.0 If I ever ask you to upload something, please use my file server. |
||||
|
|
|
|
19th July 2021, 05:55
|
#1168 | Link |
|
Registered User
Join Date: Sep 2005
Posts: 22
|
I have a request. Is it possible to make the "use legacy MIME types for font attachments" Preference apply to fonts attached in the Header Editor as well? Right now, I would have to manually enter the legacy MIME type into the MIME type box. It's a pain if there's more than a handful of fonts being attached.
Last edited by ctl-tx; 19th July 2021 at 06:00. |
|
|
|
|
19th July 2021, 09:55
|
#1169 | Link |
|
Registered User

Join Date: Jul 2006
Posts: 530
|
@Mosu
First, read and watched on TV news about the disastrous flooding in Western Europe and hope you are safe. Second, thanks for this one-of-a-kind software, really apprecitate it! Win 10 + MKVToolNix v59.0.0 I've read the MKVToolNix FAQ but am uncertain if my method is supported? I have several media files with video and audio and srt subtitles. I would like to remove some audio tracks and subtitles and then multiplex to separate files to another HDD. Thinking this will speed up the multiplex? What I can't get to work is that the video files should be kept as is one by one and not joined to one big file. Racking my brains trying to figure out the settings for batch and output to another HDD directory folder. Think I read in FAQ that batch is not possible? But... some time ago I think I got it to work... but I can't repeat that... Best regards varekai Last edited by varekai; 19th July 2021 at 10:04. Reason: . |
|
|
|
|
19th July 2021, 14:04
|
#1170 | Link | |
|
MKVToolNix author
Join Date: Sep 2002
Location: Braunschweig, Germany
Posts: 4,281
|
Quote:
__________________
Latest MKVToolNix is v83.0 If I ever ask you to upload something, please use my file server. |
|
|
|
|
|
21st July 2021, 05:08
|
#1171 | Link | |
|
李姗倩 Lǐ Shān Qiàn
Join Date: Nov 2002
Posts: 1,340
|
If Header Editor can do that, maybe the attachment MIME types should be automatically updated while MKV-to-MKV transmuxing, when the user opts out from using "font/".
Quote:
On the other hand, "zh-yue" is registered and explicitly marked as "obsoleted" since more than 10 years ago, with "Preferred-Value: yue". Although zh-yue is still valid, it's no more preferred. The real bad legacy, though, may be "application/vnd.ms-opentype" for OTF. This one is not an x- type, nor registered. So technically it's really invalid (or are there some kind of exceptions for "vnd." ?). |
|
|
|
|
|
21st July 2021, 08:49
|
#1172 | Link | |
|
MKVToolNix author
Join Date: Sep 2002
Location: Braunschweig, Germany
Posts: 4,281
|
Quote:
__________________
Latest MKVToolNix is v83.0 If I ever ask you to upload something, please use my file server. |
|
|
|
|
|
24th July 2021, 11:23
|
#1173 | Link |
|
Registered User
Join Date: Sep 2004
Location: France
Posts: 367
|
Hello and thanks for the latest update.
- I don't really understand the new 'Default' track system. Before this update, there were automatically only one (the first) track that was marked as default, one video, one audio and one subtitle track, now, every track is marked as Default, is this normal ? I manually unselect the other tracks to keep only one of each type as default, do I need to or can I keep them all as Default? - Since the latest version, the files are not added in the correct order if there's numbers in the first chars, even if they are selected in the right order in the 'Add window' 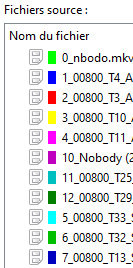 Before this update, the file "10_..." was added after the file "9_...", I don't really understand why this the "10_..." file is added after the "4_...' PS : in this example, "0_..." is video, "1_..." to "4_..." are audio files, other files are subtitles (idx/sub and SRT) Last edited by LeMoi; 24th July 2021 at 11:26. |
|
|
|
|
24th July 2021, 13:10
|
#1174 | Link | |||
|
MKVToolNix author
Join Date: Sep 2002
Location: Braunschweig, Germany
Posts: 4,281
|
Quote:
Here's the current wording from the spec notes: Quote:
MKVToolNix was changed to match the current specs. If you're interested in the details, they're discussed here and here. Quote:
That being said: I do have such a numbers-aware sorting algorithm in MKVToolNix already and use it in other appropriate places. I'll simply switch to that one which should both fix your issue & keep feature request 2866 working.
__________________
Latest MKVToolNix is v83.0 If I ever ask you to upload something, please use my file server. Last edited by Mosu; 24th July 2021 at 13:13. |
|||
|
|
|
|
24th July 2021, 16:09
|
#1175 | Link | |
|
Registered User
Join Date: Sep 2004
Location: France
Posts: 367
|
Thanks for your answer about the 'default' flag, I got it.
Quote:
I'll use two-digits numbers if there are more than 9 tracks until maybe there'll be a fix |
|
|
|
|
|
24th July 2021, 16:38
|
#1176 | Link |
|
MKVToolNix author
Join Date: Sep 2002
Location: Braunschweig, Germany
Posts: 4,281
|
Well, it's not an OS-level thing (Windows x vs Windows y vs Linux), but a per-application thing. You probably mean Windows Explorer in WinXP vs its variant in Win7.
The thing is, for detecting sequentially-numbered files (one of the prerequisites) I need to process them in numerical order so that the file numbered N comes directly before N+1. There really is no guarantee for me, the application, that the file names handed over either via the operating system (via drag & drop), from an application-specific "open file" dialog or from the command line (think of Windows' "send to" feature) are sorted. Therefore MKVToolNix must do so. Earlier versions didn't have the aforementioned feature, therefore they didn't care about the order. But like I said, should be easy to fix.
__________________
Latest MKVToolNix is v83.0 If I ever ask you to upload something, please use my file server. |
|
|
|
|
24th July 2021, 17:16
|
#1177 | Link | ||
|
MKVToolNix author
Join Date: Sep 2002
Location: Braunschweig, Germany
Posts: 4,281
|
Quote:
Quote:
There are several avenues for automating such processes, including implementing something around the command-line tool mkvmerge or using third-party applications.
__________________
Latest MKVToolNix is v83.0 If I ever ask you to upload something, please use my file server. |
||
|
|
|
|
24th July 2021, 17:23
|
#1178 | Link | |
|
MKVToolNix author
Join Date: Sep 2002
Location: Braunschweig, Germany
Posts: 4,281
|
Quote:
__________________
Latest MKVToolNix is v83.0 If I ever ask you to upload something, please use my file server. |
|
|
|
|
|
24th July 2021, 19:24
|
#1179 | Link |
|
MKVToolNix author
Join Date: Sep 2002
Location: Braunschweig, Germany
Posts: 4,281
|
The latest continuous builds have the sorting issue
sorted 😊
__________________
Latest MKVToolNix is v83.0 If I ever ask you to upload something, please use my file server. |
|
|
|
|
25th July 2021, 04:54
|
#1180 | Link |
|
Registered User
Join Date: Oct 2013
Posts: 207
|
Why is it that MediaINFO says my video has a name but MKVToolnix doesn't show that name nowhere inside the file? I mean the track itself has been "named" but I am not seeing anywhere where this information is stored, so I can remove or edit...
EDIT: located in the HEADER editor. Is there a problem if we remove this element? |
|
|
|
 |
| Tags |
| matroska |
| Thread Tools | Search this Thread |
| Display Modes | |
|
|





 Linear Mode
Linear Mode

