Welcome to Doom9's Forum, THE in-place to be for everyone interested in DVD conversion. Before you start posting please read the forum rules. By posting to this forum you agree to abide by the rules. |
 25th July 2010, 13:42
25th July 2010, 13:42
|
#81 | Link | |
|
Avisynth Developer
Join Date: Jan 2003
Location: Melbourne, Australia
Posts: 3,167
|
Quote:
I have been avoiding spoon feeding this discussion too much because I am hoping someone will come up with some ideas that do not paint one into a corner. Just about every way I look at this something always comes unglued somewhere. My first thought about the API text was existing calls as ANSI, add new calls for UTF8, but that has problems. And yes I really, really don't want existing scripts or applications to stop working. Thoughts? @krieger2005, UTF16BE/LE, UTF32BE/LE are dead easy, I do not have any difficulties with 16 or 32 bit file encoding. The hard part is 8 bit byte encodings. The state of play has to be 8 bit ansi codepage encoding has priority. That is what works now and should continue to work in the future. UTF-8 is probably going to have to be externally identified. Either by a BOM, some reserved opening sequence on the first line of the file or some other devious scheme. |
|

|

|
|
25th July 2010, 13:48
|
#82 | Link | ||||
|
Registered User

Join Date: Oct 2003
Location: Germany
Posts: 377
|
Quote:
Quote:
ANSI still have the first 7 Bits in common with ASCII and UTF-8. And all the scripts i know does not use special character above the value of 127. And even for this case: it would be practicable to Add the Codepage-Command, so that the Avisynth Parser can convert it internally to UTF-8. Quote:
Quote:
EDIT: Sorry forgot the Algorithm: 1. Detect BOM (i will not describe this) 2. if BOM couldn't be detected: Code:
*char_codes = ".{}()=";
for(int i =0; i < min(filesize,50); i++)
b = read_byte_from_file
if(strchr(char_codes, b) != NULL)
look if previous byte was a 0 // UTF 16LE ??
look if next byte is a 0 // UTF16BE ??
if(UTF16LE)
look if the three previous byte are 0 // UTF32LE
if(UT16BE)
look if the three next bytes are 0
Last edited by krieger2005; 25th July 2010 at 13:58. |
||||
|
|
|
|
25th July 2010, 15:10
|
#83 | Link | |
|
Registered User
Join Date: Oct 2003
Location: Germany
Posts: 377
|
Quote:
But, as i stated above i prefer the Definition of the used Charsed inside the File istead definening somewhere outside something. This way it get just the same as HTML does in their Files. There is still one difference. I have heard here from people that they use Codepages so the Script works in foreign Languages. Others use ANSI. But: What part of the Script use Characters above the 127 Bounds (and not in comments)? Based on the Answer of this Question, i think you can decide to Support ANSI as Fallback or just suppose the Script to be an UTF-8 Script. |
|
|
|
|
|
25th July 2010, 16:04
|
#84 | Link | |
|
Compiling Encoder

Join Date: Jan 2007
Posts: 1,348
|
Quote:
(outside of Import's currently planned handling, as import will have the file encoding to handle the situation) something similar to the other global variables like OPT_UseWaveExtensible, except that this new variable can't be set within scripts to avoid issues that would bring. something like Code:
AVSValue y = AVSValue( true ); env->SetVar( "$OPT_EvalIsUTF8", y ); this would technically complicate Import though, as it would need to handle dealing with this variable... Last edited by kemuri-_9; 25th July 2010 at 16:08. |
|
|
|
|
|
25th July 2010, 16:19
|
#85 | Link |
|
Join Date: Mar 2006
Location: Barcelona
Posts: 5,034
|
Maybe I'm missing something but why would we need UTF-8 at all? What about either 8 bit Ansi or UTF-16 as choices?
The advantage would be that both encodings are easily identified, whether there is a BOM in UTF-16 or not. |
|
|
|
|
25th July 2010, 17:41
|
#86 | Link |
|
Registered User
Join Date: Dec 2008
Posts: 589
|
Notepad and most editors, when you select Unicode at Save as, they'd default at UTF-8. You would have to do 2-3 extra clicks to select on purpose UTF-16.
Once you say your app support Unicode, people would naturally assume you support UTF-8 too, so they'd be constantly surprised if their scripts fail. So you'd have to support UTF-8 anyways. kemuri - you could also use an environment variable for that, I think. ps. Would installing two libraries be possible, for example avisynth.dll and avisynthw.dll for unicode ? maybe have some "Stub" or whatever it's called that would then load the appropriate dll depending on how it's initialized? ps2. Well ok, maybe not Notepad, which has ASCII, then Unicode, then Unicode Big Endian and then UTF-8, at least on my Windows 2003, but other editors have UTF-8 first, like for example the popular Ultraedit: 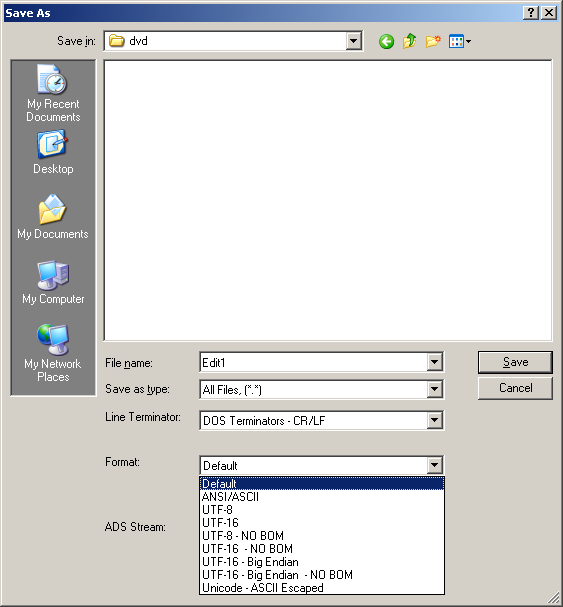
Last edited by mariush; 25th July 2010 at 17:46. |
|
|
|
|
25th July 2010, 17:50
|
#87 | Link | |
|
Join Date: Mar 2006
Location: Barcelona
Posts: 5,034
|
Quote:
|
|
|
|
|
|
25th July 2010, 18:27
|
#88 | Link |
|
Registered User
Join Date: Dec 2008
Posts: 589
|
When you have a 15-25 thousand car and chances of losing it for a day, you're more careful about that sort of thing. However, even so it will still happen to screw up.
People won't be as careful with a script as with a car, and for lots of people it would be routine, automatism, and they'd expect for something to work as it works with other programs - most won't even read the documentation, as I'm sure you didn't read the manual for Windows or other programs you have first. People will just make mistakes a lot and will be pissed and will fill the forum and most won't even understand the difference between UTF-8 and UTF-16 and won't care to learn - they just want to convert a video. I've been reading Raymond Chen's blog for years (he's a guy that worked at Microsoft on Windows 95 and still works there) and I highly recommend you browse the posts in the History section... I've learned to appreciate the extend Microsoft went to preserve compatibility with lots of things as operating systems improved and often found some things I thought to be wrong to be actually quite smart and appropriate. I've also found out that we often make assumptions that are not really true in the real world - open source programmers and small developers don't have access to millions of people using the software to know how they think so just assuming they won't use or that they'll learn not to use UTF-8 is bad and won't work in reality. |
|
|
|
|
25th July 2010, 19:04
|
#89 | Link | |
|
Avisynth language lover
Join Date: Dec 2007
Location: Spain
Posts: 3,431
|
Quote:
Especially (but not limited to) filenames - which is what I thought was the main point of this thread (or at least the starting point). |
|
|
|
|
|
25th July 2010, 19:38
|
#90 | Link | |
|
Registered User
Join Date: Oct 2003
Location: Germany
Posts: 377
|
Quote:
This is the reason why i asked if it is really usefull to be backward compatible. The reason why i suggest UTF8 was (i does not know the internals of Avisynth), that i thought, that avisynth serve the Data of the script to the Plugins after it has parsed it. So the main point is: how to should save avisynth the data internally in the parsing step? Support two formats and supporting two interfaces is one possiblity. But why should one do this? The Benefit of UTF8 is, that it is represented character by a bytestream. So, every old Plugin can be still used with the old interface without a recompile (no wchar, no int for UTF16 character, simply char*). But maybe i misunderstood the point how avisynth works internally. |
|
|
|
|
|
25th July 2010, 20:16
|
#91 | Link | |
|
Compiling Encoder
Join Date: Jan 2007
Posts: 1,348
|
Quote:
a user could have happened to set the environment variable to 'true' and then they use a program that isn't up-to-date in this regard expecting to use ASCII strings as things stand now. But due to the environment variable, avisynth will be expecting UTF8 strings. this would very likely cause unpredictable results and possibly even crashes. don't even say 'use the registry' either, that's asking to get blasted with a shotgun. If this route is actually taken, Import() would be required to do something like 1) backup the current value of the variable, whatever it is. 2) read in the file, detecting the encoding as necessary 3) set the variable to be false for the normal ASCII files, otherwise set to true and use UTF-16 -> UTF-8 conversion before passing to Eval(), if necessary. 4) restore the backed-up variable. doing this with environment variables is ugly especially since they are string values. the registry is unusable as it can break when multiple instances of avisynth are being used simultaneously. this is why i proposed to just keep this handling localized within avisynth. |
|
|
|
|
|
25th July 2010, 20:26
|
#92 | Link | |||
|
Avisynth language lover
Join Date: Dec 2007
Location: Spain
Posts: 3,431
|
Quote:
Quote:
Quote:
|
|||
|
|
|
|
27th July 2010, 07:03
|
#93 | Link |
|
Registered User
Join Date: Mar 2004
Posts: 889
|
Alternate proposal (similar to shell script headers) for file format:
1) Support 8-bit local codepage and UTF-8 only 2) BOM is optional and ignored (it is optional for UTF-8 plain text files anyway) 3) All UTF-8 encoded AVS files must have a special comment like "#! UTF-8" at the very first line. If it is not found, the file is assumed to be in 8-bit local code page encoding (irrespective of BOM). 99.999% full backward compatibility with existing scripts and easy to implement. |
|
|
|
|
21st May 2011, 14:02
|
#94 | Link |
|
Software Developer
 
Join Date: Jun 2005
Location: Last House on Slunk Street
Posts: 13,248
|
Doesn't look like that thread ever came to final conclusion. And even if it eventually will, Unicode (UTF8) support will only be in new versions, not in the old 2.5.x series, right?
So I guess I will stick with the VfW interface for now, which at least should support Unicode names... I know that this won't work if Unicode strings are used inside the Avisynth script, but at least I can open the AVS file, if the name of the AVS file itself contains Unicode characters. (Still I have no clue why VFW on my system apparently opens such files successfully, but then reports that there are no streams)
__________________
Go to https://standforukraine.com/ to find legitimate Ukrainian Charities 🇺🇦✊ Last edited by LoRd_MuldeR; 21st May 2011 at 14:06. |
|
|
|
|
21st May 2011, 15:06
|
#95 | Link |
|
Compiling Encoder
Join Date: Jan 2007
Posts: 1,348
|
indeed, avisynth does not support utf-8 within scripts and API calls, this includes the basic 'Import(file.avs)' call necessary to load existing scripts into avisynth via the API.
when support does come, it is very likely that it will not be backported to earlier releases either. you could always work around the vfw interface not failing for when the file doesn't exist by doing a _waccess( filepath, 0 ) check beforehand. |
|
|
|
|
21st May 2011, 15:14
|
#96 | Link | ||
|
Software Developer
Join Date: Jun 2005
Location: Last House on Slunk Street
Posts: 13,248
|
Quote:
I currently won't be able to import that script file with Avisynth' native API, but I am able to open the file with AVIFileOpenW(). Does Avisynth' VFW wrapper fail internally in that case? At least I have not been able to successfully load a simple AVS file with Unicode-characters in the file name this way... Quote:
__________________
Go to https://standforukraine.com/ to find legitimate Ukrainian Charities 🇺🇦✊ Last edited by LoRd_MuldeR; 21st May 2011 at 15:45. |
||
|
|
|
|
21st May 2011, 16:35
|
#97 | Link | |
|
Compiling Encoder
Join Date: Jan 2007
Posts: 1,348
|
Quote:
Code:
entry -> Load( OLEStr, mode ) unchecked convert OLEStr -> char *filename (native/oem codepage - not utf-8) copy filename to a member variable ... IScriptEnvironment->Invoke( "Import", filename ) ... same code flows as AVS API. It's Import() that throws an error if the file doesn't exist, and it primarily uses xxxxxA versions of the windows API (avisynth is compiled with MBCS after all). So if it is working with utf-16 filenames that do not map to the native/oem codepage, that's quite surprising. |
|
|
|
|
|
21st May 2011, 17:50
|
#98 | Link |
|
Software Developer
Join Date: Jun 2005
Location: Last House on Slunk Street
Posts: 13,248
|
Yup, that's clearly the reason why it doesn't work with Unicode (non-Latin1) file names, even when AVIFileOpenW() initially succeeds. I think the only workaround at this time is converting the file names to "short" names and passing the short ones AVIFileOpenW(). Short names usually survive the conversion to the local 8-Bit Codepage. It's not nice and it's not guaranteed to work (AFAIK the MSDN doc nowhere says that "short" names can't contain Unicode chars, but it does say that files are not guaranteed to have a short name), but it will probably save us most of time...
__________________
Go to https://standforukraine.com/ to find legitimate Ukrainian Charities 🇺🇦✊ Last edited by LoRd_MuldeR; 21st May 2011 at 18:01. |
|
|
|
|
21st May 2011, 19:00
|
#99 | Link |
|
Compiling Encoder
Join Date: Jan 2007
Posts: 1,348
|
Using shortnames is not likely to work either:
Import uses GetFullPathName or SearchPath (which is used depends on if there's a path delimiter in the filename) to get the fullpath/filename of the script file. these will error if the filepath contains characters outside of the native/oem codepage. |
|
|
|
|
21st May 2011, 19:59
|
#100 | Link | |
|
Software Developer
Join Date: Jun 2005
Location: Last House on Slunk Street
Posts: 13,248
|
Quote:
") However with Avisynth it works for me here, passing the "short" version of a fully-qualified path: Code:
avs2wav v1.2 [May 21 2011] by Jory Stone <jcsston@toughguy.net>, updates by LoRd_MuldeR <mulder2@gmx.de> Input: G:\ViDeOz\Music\Володимирович 菅直人 κλασικής.avs Output: Dump.wav Checking Avisynth... Done Analyzing input file... Done Opening output file... Done [Audio Info] TotalSamples: 11391413 TotalSeconds: 258 SamplesPerSec: 44100 BitsPerSample: 16 Channels: 2 AvgBytesPerSec: 176400 Dumping audio data, please wait: 0/11391413 [0%] 11391413/11391413 [100%] All samples have been dumped. Exiting.
__________________
Go to https://standforukraine.com/ to find legitimate Ukrainian Charities 🇺🇦✊ Last edited by LoRd_MuldeR; 21st May 2011 at 20:09. |
|
|
|
|
 |
|
|



 Linear Mode
Linear Mode

